# ___ Search for powershell in windows
PS C:\Users\EMHRC>
# ___ Change directories
PS C:\Users\EMHRC> cd D:\py_projects
# ___ Set content of file to var
PS D:\py_projects> $view = Get-Content "data\extracted\vehicle-data.csv"
# ___ Read line 6
PS D:\py_projects> $view[5]
6,Sat Aug 14 03:57:47 2021,8411850,car,2,VC965
# ___ Read first 5 lines
PS D:\py_projects> $view | Select-Object -First 5
# ___ OUTPUT
1,Thu Aug 19 21:54:38 2021,125094,car,2,VC965
2,Sat Jul 31 04:09:44 2021,174434,car,2,VC965
3,Sat Aug 14 17:19:04 2021,8538286,car,2,VC965
4,Mon Aug 2 18:23:45 2021,5521221,car,2,VC965
5,Thu Jul 29 22:44:20 2021,3267767,car,2,VC965
# ___ Read last 5 lines
PS D:\py_projects> $view = Get-Content "data\extracted\vehicle-data.csv"
PS D:\py_projects> $view | Select-Object -Last 5
# ___ OUTPUT
9996,Sun Aug 15 03:02:27 2021,3369206,car,2,VC965
9997,Sat Aug 7 04:24:08 2021,5886709,truck,4,VCB43
9998,Mon Aug 9 02:58:26 2021,917421,truck,4,VCB43
9999,Tue Aug 17 18:41:00 2021,2601682,truck,4,VCB43
10000,Mon Aug 9 22:56:50 2021,4833266,car,2,VC965
# ___ Read extracted file
PS D:\py_projects> $view = Get-Content "data\extracted\csv_data.csv"
PS D:\py_projects> $view | Select-Object -First 5
1,Thu Aug 19 21:54:38 2021,125094,car
2,Sat Jul 31 04:09:44 2021,174434,car
3,Sat Aug 14 17:19:04 2021,8538286,car
4,Mon Aug 2 18:23:45 2021,5521221,car
5,Thu Jul 29 22:44:20 2021,3267767,car
# ___ Read extracted file
PS D:\py_projects> $view = Get-Content "data\extracted\tsv_data.csv"
PS D:\py_projects> $view | Select-Object -First 5
2,4856,PC7C042B7
2,4154,PC2C2EF9E
2,4070,PCEECA8B2
2,4095,PC3E1512A
2,4135,PCC943ECD
# ___ Read extracted file
PS D:\py_projects> $view = Get-Content "data\extracted\fixed_width_data.csv"
PS D:\py_projects> $view | Select-Object -First 5
PTE,VC965
PTP,VC965
PTE,VC965
PTP,VC965
PTE,VC965DAG ETL Toll Data
Case Study - Python
Note: This is the same project solved in DAG Bash ETL Toll Data using BashOperator
You have been assigned a project to decongest the national highways by analyzing the road traffic data from different toll plazas.
- Each highway is operated by a different toll operator with a different IT setup that uses different file formats.
- Your job is to collect data available in different formats and consolidate it into a single file.
We will develop an Apache Airflow DAG that will:
- Use
PythonOperatorfor this project - Download the data from an online repository found here
- Unzip the file
- Extract data from a csv file
- Extract data from a tsv file
- Extract data from a fixed-width file
- Transform the data
- Load the transformed data into the staging area
Extra Powershell
To use windows powershell to view content do this:
# ___ Read combined_file
PS C:\Users\EMHRC> cd D:\py_projects
PS D:\py_projects> $view = Get-Content "data\extracted\extracted_data.csv"
PS D:\py_projects> $view | Select-Object -First 5
1,Thu Aug 19 21:54:38 2021,125094,car,2,4856,PC7C042B7,PTE,VC965
2,Sat Jul 31 04:09:44 2021,174434,car,2,4154,PC2C2EF9E,PTP,VC965
3,Sat Aug 14 17:19:04 2021,8538286,car,2,4070,PCEECA8B2,PTE,VC965
4,Mon Aug 2 18:23:45 2021,5521221,car,2,4095,PC3E1512A,PTP,VC965
5,Thu Jul 29 22:44:20 2021,3267767,car,2,4135,PCC943ECD,PTE,VC965
# ___ Read transformed_data
PS D:\py_projects> $view = Get-Content "data\extracted\transformed_data.csv"
PS D:\py_projects> $view | Select-Object -First 5
1,Thu Aug 19 21:54:38 2021,125094,CAR,2,4856,PC7C042B7,PTE,VC965
2,Sat Jul 31 04:09:44 2021,174434,CAR,2,4154,PC2C2EF9E,PTP,VC965
3,Sat Aug 14 17:19:04 2021,8538286,CAR,2,4070,PCEECA8B2,PTE,VC965
4,Mon Aug 2 18:23:45 2021,5521221,CAR,2,4095,PC3E1512A,PTP,VC965
5,Thu Jul 29 22:44:20 2021,3267767,CAR,2,4135,PCC943ECD,PTE,VC965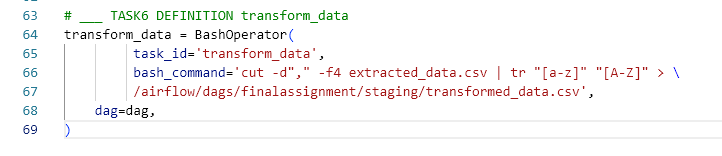
Solution
We will be using the Skills Network Cloud IDE by IBM, so we start by activating Airflow from the IDE
Create Directory
# ___ Open a terminal and create a directory
sudo mkdir -p /home/project/airflow/dags/finalassignment/stagingSet Permissions
# ___ Set permissions rwx for everyone to the directory
sudo chmod -R 777 /home/project/airflow/dags/finalassignmentCreate DAG
Script File
- Using IDE, create a new file named
ETL_toll_data.pyin/home/projectdirectory and open it in the file editor.
Imports
# ___ IMPORT libraries
from datetime import timedelta
# The DAG object; we'll need this to instantiate a DAG
from airflow.models import DAG
# Operators; you need this to write tasks!
from airflow.operators.python import PythonOperator
# This makes scheduling easy
from airflow.utils.dates import days_ago
import requests
import tarfile
import pandas as pdVariables
# ___ DEFINE input & output files
input_file = '/airflow/dags/python_etl/staging/tolldata.tgz'
extracted_dir = '/airflow/dags/python_etl/staging'
vehicle_file = '/airflow/dags/python_etl/staging/vehicle-data.csv'
tsv_in = '/airflow/dags/python_etl/staging/tollplaza-data.tsv'
tsv_out = '/airflow/dags/python_etl/staging/tsv_data.csv'
fixed_in = '/airflow/dags/python_etl/staging/payment-data.txt'
fixed_out = '/airflow/dags/python_etl/staging/fixed_width_data.csv'
extracted_vehicle = 'csv_data.csv'
combined_file = 'transformed.txt'
transformed_file = 'capitalized.txt'Arguments
# ___ ARGUMENTS
default_args = {
'owner': 'santa',
'start_date': days_ago(0), # today
'email': ['santa@gmail.com'],
'email_on_failure': True,
'email_on_retry': True,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}Definition
# ___ DAG DEFINITION
dag = DAG(
dag_id = 'ETL_toll_data',
description = 'Apache Airflow Final Assignment',
default_args = default_args,
schedule_interval=timedelta(days=1) # once daily
)Create Functions
Function 1: download_dataset
- Create a Python function named
download_datasetto download the data set from the source to the destination - Source
- Destination:
/home/project/airflow/dags/python_etl/staging
# ___ CREATE FUNCTION 1 FOR TASK 1 download_dataset
def download_dataset():
url = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0250EN-SkillsNetwork/labs/Final%20Assignment/tolldata.tgz"
# Send a GET request to the URL
with requests.get(url, stream=True) as response:
# Raise an exception for HTTP errors
response.raise_for_status()
# Open a local file in binary write mode
with open(input_file, 'wb') as file:
# Write the content to the local file in chunks
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"File downloaded successfully: {input_file}")Function 2: untar_dataset
- Create a Python function named
untar_datasetto untar the downloaded data set.
# ___ CREATE FUNCTION 2 FOR TASK 2 untar_dataset
def untar_dataset():
with tarfile.open(input_file, 'r') as tar:
tar.extractall(path = extracted_dir)
print(f"Extracted all files to {extracted_dir}")
print(os.listdir({extracted_dir}))# ___ OUTPUT
Extracted all files to /data/extracted
['fileformats.txt', 'payment-data.txt', '._tollplaza-data.tsv', 'tollplaza-data.tsv', '._vehicle-data.csv', 'vehicle-data.csv']Function 3: extract_data_from_csv
- Let’s look at the data first
- Create a function named
extract_data_from_csvto extract the fields Rowid,Timestamp,Anonymized Vehicle number, andVehicle typefrom thevehicle-data.csvfile and- save them into a file named
csv_data.csv
Review vehicle-data.csv
Here is the information provided with the file:
- vehicle-data.csv is a comma-separated values file.
- It has the below 6 fields
- Rowid - This uniquely identifies each row. This is consistent across all the three files.
- Timestamp - What time did the vehicle pass through the toll gate.
- Anonymized Vehicle number - Anonymized registration number of the vehicle
- Vehicle type - Type of the vehicle
- Number of axles - Number of axles of the vehicle
- Vehicle code - Category of the vehicle as per the toll plaza.
# ___ Read through the first few lines of vehicle-data.csv
head -n 5 vehicle-data.csv
# ___ OUTPUT
1,Thu Aug 19 21:54:38 2021,125094,car,2,VC965
2,Sat Jul 31 04:09:44 2021,174434,car,2,VC965
3,Sat Aug 14 17:19:04 2021,8538286,car,2,VC965
4,Mon Aug 2 18:23:45 2021,5521221,car,2,VC965
5,Thu Jul 29 22:44:20 2021,3267767,car,2,VC965# ___ CREATE FUNCTION FOR TASK 3 extract_data_from_csv
def extract_data_from_csv():
print("Column Extract from CSV")
# Read the contents of the file into a string
with open(vehicle_file, 'r') as infile, \
open(extracted_vehicle, 'w') as outfile:
for line in infile:
fields = line.split(',')
if len(fields) >= 4:
field_1 = fields[0]
field_2 = fields[1]
field_3 = fields[2]
field_4 = fields[3]
outfile.write(field_1 + "," + field_2 + "," + field_3 + "," + field_4 + "\n")Function 4: extract_data_from_tsv
- Let’s look at the data first
- Create a function named
extract_data_from_tsvto extract the fields Number of axles,Tollplaza id, andTollplaza code(the last 3 fields) from thetollplaza-data.tsvfile and- save it into a file named
tsv_data.csv
Review tollplaza-data.tsv
Here is the information provided with the file:
- tollplaza-data.tsv is a tab-separated values file
- It has the below 7 fields
- Rowid - This uniquely identifies each row. This is consistent across all the three files.
- Timestamp - What time did the vehicle pass through the toll gate.
- Anonymized Vehicle number
- Anonymized registration number of the vehicle
- Vehicle type - Type of the vehicle
- Number of axles - Number of axles of the vehicle
- Tollplaza id - Id of the toll plaza
- Tollplaza code - Tollplaza accounting code
# ___ Read through the first few lines of tollplaza-data.tsv Using Bash
head -n 5 tollplaza-data.tsv
# ___ OUTPUT
1 Thu Aug 19 21:54:38 2021 125094 car 2 4856 PC7C042B7
2 Sat Jul 31 04:09:44 2021 174434 car 2 4154 PC2C2EF9E
3 Sat Aug 14 17:19:04 2021 8538286 car 2 4070 PCEECA8B2
4 Mon Aug 2 18:23:45 2021 5521221 car 2 4095 PC3E1512A
5 Thu Jul 29 22:44:20 2021 3267767 car 2 4135 PCC943ECD# ___ CREATE FUNCTION FOR TASK 4 extract_data_from_tsv
def extract_data_from_tsv():
print("Column Extract from TSV")
# Read the contents of the file into a string
with open(tsv_in, 'r') as infile, \
open(tsv_out, 'w') as outfile:
for line in infile:
fields = line.split('\t')
if len(fields) >= 7:
field_1 = fields[4]
field_2 = fields[5]
field_3 = fields[6]
outfile.write(field_1 + "," + field_2 + "," + field_3 )
# because it is tab delimiter I took out the "\n" or it would add an extra line breakFunction 5: extract_data_from_fixed_width
- Create a function named
extract_data_from_fixed_widthto extract the fields Type of Payment codeandVehicle Codefrom the fixed width filepayment-data.txtand- Save it into a file named
fixed_width_data.csv - Let’s look at the data first
Review payment-data.txt
Here is the information provided with the file:
- payment-data.txt is a fixed width file
- Each field occupies a fixed number of characters.
- It has the below 7 fields:
- Rowid - This uniquely identifies each row. This is consistent across all the three files
- Timestamp - What time did the vehicle pass through the toll gate
- Anonymized Vehicle number - Anonymized registration number of the vehicle
- Tollplaza id - Id of the toll plaza
- Tollplaza code - Tollplaza accounting code
- Type of Payment code - Code to indicate the type of payment. Example : Prepaid, Cash
- Vehicle Code - Category of the vehicle as per the toll plaza
# ___ Read through the first few lines of payment-data.txt
head -n 5 payment-data.txt
# ___ OUTPUT
1 Thu Aug 19 21:54:38 2021 125094 4856 PC7C042B7 PTE VC965
2 Sat Jul 31 04:09:44 2021 174434 4154 PC2C2EF9E PTP VC965
3 Sat Aug 14 17:19:04 2021 8538286 4070 PCEECA8B2 PTE VC965
4 Mon Aug 2 18:23:45 2021 5521221 4095 PC3E1512A PTP VC965
5 Thu Jul 29 22:44:20 2021 3267767 4135 PCC943ECD PTE VC965
# ___ Max line length
wc -L payment-data.txt
# ___ OUTPUT
67 payment-data.txt# ___ CREATE FUNCTION 5 FOR TASK 5 extract_data_from_fixed_width
# ___ Start position = 58 end position = 67
def extract_data_from_fixed_width():
print("Column Extract from Fixed Width")
# Read the contents of the file into a string
start_pos = 58
end_pos = 67
with open(fixed_in, 'r') as infile, \
open(fixed_out, 'w') as outfile:
for line in infile:
wanted_line = line[start_pos:end_pos].strip()
fields = wanted_line.split(' ')
if len(fields) >= 2:
field_1 = fields[0]
field_2 = fields[1]
outfile.write(field_1 + "," + field_2 + "\n")Function 6: consolidate_data
- Create a function named
consolidate_datato create a single csv file namedextracted_data.csvby combining data from the following files: csv_data.csvtsv_data.csvfixed_width_data.csv
The final csv file should use the fields in the order given below:
Rowid, Timestamp, Anonymized Vehicle number, Vehicle type, Number of axles, Tollplaza id, Tollplaza code, Type of Payment code, and Vehicle Code
Sample Code Using Directory
- combine_csv_files(input_directory, output_file)
- Import Libraries: The script starts by importing the necessary libraries (pandas and os).
- Define Function: The combine_csv_files function takes two arguments: input_directory (the directory containing the CSV files) and output_file (the path to the output CSV file).
- List Dataframes: Initializes an empty list to hold individual dataframes.
- Iterate Files: Iterates over all files in the input directory, checking if they end with .csv.
- Read and Append: Reads each CSV file into a pandas dataframe and appends it to the list.
- Concatenate Dataframes: Uses pd.concat to concatenate all dataframes in the list into a single dataframe.
- Write Output: Writes the combined dataframe to the specified output file.
This script will create a single CSV file containing all the data from the CSV files in the specified directory.
import pandas as pd
import os
def combine_csv_files(input_directory, output_file):
# List to hold individual dataframes
dataframes = []
# Iterate over all files in the input directory
for filename in os.listdir(input_directory):
if filename.endswith(".csv"):
file_path = os.path.join(input_directory, filename)
# Read the CSV file
df = pd.read_csv(file_path)
# Append the dataframe to the list
dataframes.append(df)
# Concatenate all dataframes
combined_df = pd.concat(dataframes, ignore_index=True)
# Write the combined dataframe to the output file
combined_df.to_csv(output_file, index=False)
# Example usage
input_directory = 'path/to/your/csv/files'
output_file = 'path/to/output/combined.csv'Here is our function
# ___ CREATE FUNCTION 6 FOR TASK 6 consolidate_data: csv_data.csv tsv_data.csv fixed_width_data.csv
def consolidate_data():
# Read csv files
df1 = pd.read_csv(extracted_vehicle)
df2 = pd.read_csv(tsv_out)
df3 = pd.read_csv(fixed_out)
# Combine dfs
combined_df = pd.concat([df1,df2,df3], axis =1)
# Write the combined df to the output file
combined_df.to_csv(combined_file, index = False)Function 7: transform_data
- Create a function named
transform_datato - Transform the
vehicle_typefield inextracted_data.csvinto capital letters and - Save it into a file named
transformed_data.csvin the staging directory.
# ___ CREATE FUNCTION 7 FOR TASK 7 transform_data
def transform_data():
print("Inside Transform File")
# Read content of file into string
with open(combined_file, 'r') as infile, \
open(transformed_file, 'w') as outfile:
for line in infile:
fields = line.split(',')
fields[3] = fields[3].upper()
outfile.write("," .join(fields) )
# I took out the "\n" or it would add an extra line breakCreate Tasks
- Create 7 tasks using Python operators that does the following using the Python functions created in Create Functions:
- download_dataset
- untar_dataset
- extract_data_from_csv
- extract_data_from_tsv
- extract_data_from_fixed_width
- consolidate_data
- transform_data
- Define the task pipeline based on the details given below:
| Task | Functionality |
|---|---|
| First task | download_data |
| Second task | unzip_data |
| Third task | extract_data_from_csv |
| Fourth task | extract_data_from_tsv |
| Fifth task | extract_data_from_fixed_width |
| Sixth task | consolidate_data |
| Seventh task | transform_data |
Task 1: download
# ___ TASK 1 DEFINITION :
download_data = PythonOperator(
task_id='download_data',
python_callable=download_dataset,
dag=dag,
)Task 2: unzip
# ___ TASK 2 DEFINITION :
unzip = PythonOperator(
task_id='unzip',
python_callable=untar_dataset,
dag=dag,
)Task 3: extract_from_csv
# ___ TASK 3 DEFINITION :
extract_from_csv = PythonOperator(
task_id='extract_from_csv',
python_callable=extract_data_from_csv,
dag=dag,
)Task 4: extract_from_tsv
# ___ TASK 4 DEFINITION :
extract_from_tsv = PythonOperator(
task_id='extract_from_tsv',
python_callable=extract_data_from_tsv,
dag=dag,
)Task 5: extract_from_fixed
# ___ TASK 5 DEFINITION :
extract_from_fixed = PythonOperator(
task_id='extract_from_fixed',
python_callable=extract_data_from_fixed_width,
dag=dag,
)Task 6: consolidate
# ___ TASK 5 DEFINITION :
consolidate = PythonOperator(
task_id='consolidate',
python_callable=consolidate_data,
dag=dag,
)Task 7: transform
# ___ TASK 5 DEFINITION :
transform = PythonOperator(
task_id='transform',
python_callable=transform_data,
dag=dag,
)Create Pipeline
# ___ PIPELINE
download >> unzip >> extract_from_csv >> extract_from_tsv >> extract_from_fixed >> consolidate >> transformSubmit DAG
# ___ SUBMIT DAG file into the directory
cp ETL_toll_data.py airflow/dags
# ___ In case of errors use
airflow dags list-import-errorsVerify DAG
airflow dags list | grep "ETL_toll_data.py"List Tasks
- You can view the tasks in the Web UI in the Graph tab or
- Use CLI as shown below
# ___ List Tasks
airflow tasks listObserve DAG
Unpause DAG
- You can unpause the DAG from within the Web UI or
- Use CLI as shown below
# ___ UNPAUSE DAG
airflow dags unpause ETL_toll_dataTrigger DAG
- Use the Web UI to trigger the DAG
- Manual Trigger is far right next to links