Data Repositories
Data mining repositories store data for reporting, analysis, and deriving insights, but their purpose, types of data stored, and how data is accessed differs. Here is a summary of what we’ll cover in this document:
| Repository | Description | Optimized for | Limitation | Use Cases |
|---|---|---|---|---|
| RDBM | Built on principles of flat files Tabular format w/rows & columns Well defined structure & schema ACID compliant Powerful when joining tables |
Data operations SQL & other querying Storage, retrieval, processing of large vol of data Uses keys to relate tables together Query mulitple tables at once |
Not for semi & unstructured data Migrating 2 RDBMs in only possible if both have identical schema Restricted to input values specified by schema |
OLTP Data Warehouses- OLAP IoT solutions |
| NoSQL - Non-Relational DBs | Stores any data: Key-value as collection of key-value pairs Document-based stored in 1 document Column-based stored in cells grouped in columns not rows. Then grouped as family Graph-based stored in graphical model |
Speed, flexibility, scale, schema-less Handles large V of uns/ structured data Easily scales out Great for Big Data, built for specific data models |
||
| Data Warehouse | Central repository merging data from disparate sources Stores ETL historical, cleansed, categorized data |
Bot Tier: db servers - relational, non-relational Middle Tier: OLAP server Top Tier: client front-end for querying, reporting, analyzing |
||
| Data Mart | Subsection of D Warehouse Built for a specific business function |
Provides users with most relevant data | ||
| Data Lakes | Stores ALL types of data in their original format No schema Repository of raw data |
Scales fast No schema Ability to repurpose any data Big Data capable |
||
| Data Lakehouse | Combines both Warehouse & Lake | Warehouse: Cost effective, great performance, structure, governance, management, machine learning high loads, fast Lake: any type of Data at low cost |
||
| Big Data Stores | Computational & storage infrastructure to store, scale, process very large data sets |
Overall, data repositories help to isolate data and make reporting and analytics more efficient and credible while also serving as a data archive. Several factors influence the choice of database, such as
- the data type and structure
- querying mechanisms
- latency requirements
- transaction speeds, and
- intended use of the data.
Relational RDBMs
- Built on the organizational principles of flat files, with data organized in tabular format with rows and columns following a well-defined structure and schema
- Unlike flat files, RDBMs are optimized for data operations and querying with SQL and other languages and
- Optimized for storage, retrievel and processing of data for large volumes of data, unlike spreadsheets

- RDBMS use primary keys that relate tables to each other
- That allows you query multiple tables at once
- Data can be extracted from RDBMs using SQL, of course you can use other languages such as R or python… But SQL seems to be the most popular
Can retrieve millions of records in seconds using SQL
Use Cases
- OLTP - Online Transaction Processing application
- Data Warehouses - OLAP
- IoT Solutions
Limitations
- NOT suited for semi-structured and unstructured data
- Migration between two RDBMs’s is possible only when the source and destination tables have identical schema and data types
- Entering a value greater than the defined length of a data field results in loss of information
NoSQL - Non-Relational DBs
- Not Only SQL emerged in response to the volume, diversity, and speed at which data is being generated today, mainly influenced by advances in cloud computing, the Internet of Things, and social media proliferation.
- Built for speed, flexibility, and scale, non-relational databases made it possible to store data in a schema-less or free-form fashion.
- NoSQL is widely used for processing big data and are built for specific data models
- Has flexible schemas, do not use a traditional row/column/table database design
- Do not typically use SQL to query data
- Its advantage is to handle large volumes of structured, semi-structured, and unstructured data
- Its ability to run as a distributed system scaled across multiple data centers
- Easily scales out with the addition of new nodes
- Simple design, better control over availability, and improved scalability that makes it agile, flexible, and support quick iterations
- Any data can be stored in NoSQL databases
- Key-value data - stored as a collection of key-value pairs. Great for storing user session data and user preferences
- Redis, Memcached, DynamDB are examples
- Document-based - store each record and its associated data within a single document. They enable flexible indexing, powerful ad hoc queries, and analytics over collections of documents
- Preferred for eCommerce platforms, medical records, CRM, analytics platforms
- Not best for complex search queries and multi-operation tansactions
- MongoDB, DocumentDB, CouchDB, Cloudant
- Column-based - store data in cells grouped as columns of data instead of rows. A logical grouping of columns, that is, columns that are usually accessed together, is called a column family.
- For example, a customer’s name and profile information will most likely be accessed together but not their purchase history.
- So,customer name and profile information data can be grouped into a column family.
- Since column databases store all cells corresponding to a column as a continuous disk entry, accessing and searching the data becomes very fast.
- Column databases can be great for systems that require heavy write requests, storing time-series data, weather data, and IoT data.
- Not good for complex queries or change your querying patterns frequently.
- The most popular column databases are Cassandra and HBase.
- Graph-based - use a graphical model to represent and store data.
- They are particularly useful for visualizing, analyzing, and finding connections between different pieces of data.
- The circles arenodes contain the data.
- The arrows represent relationships.
- Graph databases are an excellent choice for working with connected data, which is data that contains lots of interconnected relationships.
- Graph databases are great for social networks, real-time product recommendations, network
- diagrams, fraud detection, and access management.
- Not good if you want to process high volumes of transactions because graph databases are not optimized for large-volume analytics queries.
- Neo4J and CosmosDB are some of the more popular graph databases.
- Some non-relational dbs come with their own querying tools such as CQL for Cassandra and GraphQL for Neo4J
- Key-value data - stored as a collection of key-value pairs. Great for storing user session data and user preferences

Data Warehouse
Traditionally, data warehouses are known to store relational data from transactional systems and operational databases such as CRM, ERP, HR, and Finance applications.
But with the emergence of NoSQL technologies and new data sources, non-relational data repositories are also being used for data warehousing.
A data warehouse works as a central repository that merges information coming from disparate sources and consolidates it through the extract, transform, and load process, also known as the ETL process, into one comprehensive database for analytics and business intelligence.
DW store current and historical data that has been cleansed, conformed, and categorized. It has already been modeled and structured for a specific purpose, and it’s analysis ready.
At a very high-level, the ETL process helps you to extract data from different data sources, transform the data into a clean and usable state, and load the data into the enterprise’s data repository
Examples include:
- Teradata Enterprise Data Warehouse
- Oracle Exadata
- IBM Db2 Warehouse on cloud
- IBM Netezza Performance Server
- Amazon RedShift
- BigQuery by Google
- Cloudera’s Enterprise Data Hub
- Snowflake Cloud Data Warehouse
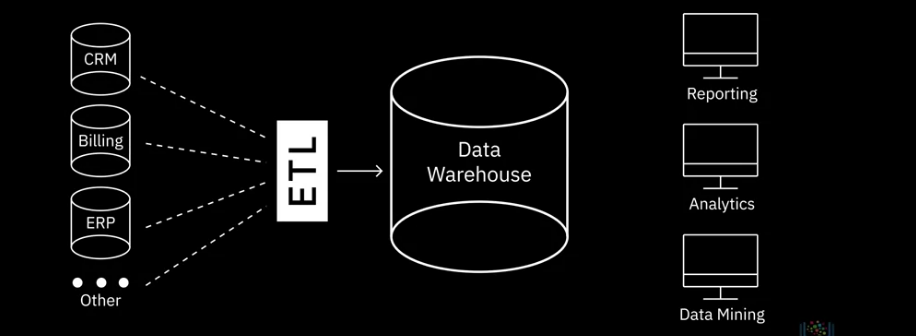
Tiered Architecture
Typically, a data warehouse has a three-tier architecture:
- Bottom tier includes the db servers, which could be relational, non-relational or both that extract data from different sources
- Middle tier, OLAP Server, a category of software that allow users to process and analyze information coming from multiple db servers
- Top tier, the client front-end layer which includes all the tools and applications used for querying, reporting, and analyzing data
Data Mart
Is a subsection of the data warehouse, built specifically for a particular business function, purpose, or community of users.
Its purpose is to provide users with data that is most relevant to them when they need it.
- Sales, or finance groups in an organization
- There are 3 types of Data Marts:
- dependent - sub-section of an enterprise data warehouse.
- They pull data from an enterprise data where it has already been cleaned and transformed
- independent - are created from sources other than an enterprise data warehouse, such as internal operational systems or external data.
- They carry out the transformation since data is coming from operational systems and external sources.
- Hybrid - combine inputs from data warehouses, operational systems, and external systems. The difference also lies in how data is extracted from the source systems, the transformations that need to be applied, and how the data is transported into the mart
- dependent - sub-section of an enterprise data warehouse.
Data Lakes
Data Lakes or Data Marts have historically been relational, since much of the traditional enterprise data has resided in RDBMSes.
However, with the emergence of NoSQL technologies and new sources of data, non-relational data repositories are also now being used for Data Warehousing.
DL is a data repository that can store large amounts of structured, semi-structured, and unstructured data in their native format. Think of it as the storage in a large restaurant.
- While a data warehouse stores data that has been cleaned, processed, and transformed for a specific need, you do not need to define the structure and schema of data before loading into the data lake.
- You do not even need to know all of the use cases for which you will ultimately be analyzing the data.
- A data lake exists as a repository of raw data in its native format, straight from the source, to be transformed based on the use case for which it needs to be analyzed.
- This does not mean that a data lake is a place where data can be dumped without governance. While in the data lake, the data is appropriately classified, protected, and governed. A data lake is a reference architecture that is independent of technology.
- Data lakes combine a variety of technologies that come together to facilitate agile data exploration for analysts and data scientists.
- Data lakes can be deployed using
- Cloud Object Storage, such as Amazon S3, or
- large-scale distributed systems such as Apache Hadoop, used for processing Big Data.
- They can also be deployed on different relational database management systems,
- as well as NoSQL data repositories that can store very large amounts of data.
- Data lakes offer a number of benefits, such as:
- The ability to store all types of data – unstructured data such as documents, emails, PDFs, semi-structured data such as JSON, XML, CSV, and logs, as well as structured data from relational databases
- The agility to scale based on storage capacity – growing from terabytes to petabytes of data
- Saving time in defining structures, schemas, and transformations since data is imported in its original format and
- The ability to repurpose data in several different ways and wide-ranging use cases. This is extremely beneficial as it is hard for businesses to foresee all the different ways in which you could potentially leverage their data in the future.
- Some of the vendors that provide technologies, platforms, and reference architectures for data lakes include
- Amazon
- Cloudera
- IBM
- Informatica
- Microsoft Oracle
- SAS
- Snowflake
- Teradata
- Zaloni
Data LakeHouse
Combines both Data Warehouse and Data Lakes and focuses on the pluses of each.
- we get the cost effectiveness of a data lake,
- and we get the performance and structure of a data warehouse.
- the lake house lets us store data from the exploding number of new sources in a low cost way, comparable to Data Lake, and
- then leverages built in data management and governance layers to allow us to power both business intelligence and high performance machine learning workloads quickly, comparable to Data Warehouse
Big Data Stores
Include distributed computational and storage infrastructure to store, scale, and process very large data sets.
ETL & ELT
Now we come to the process that is at the heart of gaining value from data.
- The Extract, Transform, and Load process, or ETL.
- ETL is how raw data is converted into analysis-ready data.
- It is an automated process in which you gather raw data from identified sources, extract the information that aligns with your reporting and analysis needs, clean, standardize, and transform that data into a format that is usable in the context of your organization; and
- load it into a data repository
While ETL is a generic process, the actual job can be very different in usage, utility, and complexity.
- Extract is the step where data from source locations is collected for transformation. Data extraction could be through
- Batch processing, meaning source data is moved in large chunks from the source to the target system at scheduled intervals.
- Tools for batch processing include Stitch and Blendo.
- Stream processing, which means source data is pulled in real-time from the source and transformed while it is in transit and before it is loaded into the data repository.
- Tools for stream processing include Apache Samza, Apache Storm, and Apache Kafka.
- Batch processing, meaning source data is moved in large chunks from the source to the target system at scheduled intervals.
- Transform involves the execution of rules and functions that convert raw data into data that can be used for analysis.
- Load is the step where processed data is transported to a destination system or data repository. It could be:
- Initial loading, that is, populating all the data in the repository
- Incremental loading, that is, applying ongoing updates and modifications as needed periodically or
- Full refresh, that is, erasing contents of one or more tables and reloading with fresh data
- Load verification—which includes data checks for missing or null values, server performance, and monitoring load failures, are important parts of this process step.
We’ll cover ETL & ELT in another section of the site.
Data Platform
The architecture of a data platform consists of five layers, each layer responsible for a specific set of tasks. These five layers are
- Data Ingestion or Data Collection Layer
- Data Storage and Integration Layer
- Data Processing Layer
- Analysis and User Interface Layer
- Data Pipeline Layer
Data Integration
In the field of analytics and data science, data integration includes
- accessing, queueing, or
- extracting data from operational systems transforming and
- merging extracted data either logically or physically
- data quality and governance, and
- delivering data through an integrated approach for analytics purposes
For example, to make customer data available for analytics, you would need to extract individual customers’ information from operational systems such as sales, marketing, and finance. You would then need to provide a unified view of the combined data so that your users can access, query, and manipulate this data from a single interface to derive statistics, analytics, and visualizations.
How does a data integration platform relate to ETL and data pipelines?
- While data integration combines disparate data into a unified view of the data,
- A data pipeline covers the entire data movement journey from source to destination systems. In that sense, you use a data pipeline to perform data integration, while ETL is a process within data integration.
Data integration solutions typically support the following capabilities:
- An extensive catalog of pre-built connectors and adopters that help you connect and build integration flows with a wide variety of data sources such as databases, flat files, social media data, APIs, CRM and ERP applications.
- Open-source architecture that provides greater flexibility and avoids vendor lock-in.
- Optimization for both batch processing of large-scale data and continuous data streams, or both.
- Integration with Big Data sources.
- Specific demands around data quality and governance, compliance, and security.
- Portability, which ensures that as businesses move to cloud models, they should be able to run their data integration platforms anywhere.
- And data integration tools that are able to work natively in a single cloud, multi-cloud, or hybrid cloud environment.
There are many data integration platforms and tools available in the market, ranging from commercial off-the-shelf tools to open-source frameworks.
- IBM offers a host of data integration tools targeting a range of enterprise integration scenarios, such as
- Information Server for IBM
- Cloud Pak for Data
- IBM Cloud Pak for Integration
- IBM Data Replication
- IBM Data Virtualization Manager
- IBM InfoSphere Information Server on Cloud
- IBM InfoSphere DataStage
- Talend’s data integration tools include
- Talend Data Fabric
- Talend Cloud
- Talend Data Catalog
- Talend Data Management
- Talend Big Data
- Talend Data Services
- Talend Open Studio
- SAP, Oracle, Denodo, SAS, Microsoft, Qlik, and TIBCO are some of the other vendors that offer data integration tools and platforms.
- Open-source frameworks include
- Dell Boomi
- Jitterbit
- SnapLogic.
There are a significant number of vendors who are offering cloud-based Integration Platform as a Service, or iPaaS, as a hosted service via virtual private cloud or hybrid cloud. Such as
Adeptia Integration Suite
Google Cloud’s Cooperation 534
IBM’s Application Integration Suite on Cloud
Informatica’s Integration Cloud.
Data Extraction
SQL
Data can be extracted from RDBMs using SQL, of course you can use other languages such as R or python… But SQL seems to be the most popular
CQL & GraphQL
Some non-relational dbs come with their own querying tools such as CQL for Cassandra and GraphQL for Neo4J
API
Application Programming Interfaces (or APIs) are also popularly used for extracting data from a variety of data sources. APIs are invoked from applications that require the data and access an end-point containing the data.
End-points can include databases, web services, and data marketplaces. APIs are also used for data validation.
Web Scraping
Also known as screen scraping or web harvesting, is used for downloading specific data from web pages based on defined parameters.
Among other things, web scraping is used to extract data such as text, contact information, images, videos, podcasts, and product items from a web property.
RSS Feeds
Rss feeds are another source typically used for capturing updated data from online forums and news sites where data is refreshed on an ongoing basis.
Data Streams
Data streams are a popular source for aggregating constant streams of data flowing from sources such as instruments, IoT devices and applications, and GPS data from cars.
Data streams and feeds are also used for extracting data from social media sites and interactive platforms.
Data Exchange Platforms
Data Exchange platforms allow the exchange of data between data providers and data consumers. Data Exchanges have a set of well-defined exchange standards, protocols, and formats relevant for exchanging data.
Data Wrangling
Data wrangling, also known as data munging, is an iterative process that involves data exploration, transformation, validation, and making data available for a credible and meaningful analysis.
Some of the tasks involved in wrangling are:
Structuring
This task includes actions that change the form and schema of your data. The incoming data can be in varied formats. You might, for example, have some data coming from a relational database and some data from Web APIs.
In order to merge them, you will need to change the form or schema of your data. This change may be as simple as changing the order of fields within a record or dataset or as complex as combining fields into complex structures.
- Joins and Unions are the most common structural transformations used to combine data from one or more tables. How they combine the data is different.
- Joins combine columns. When two tables are joined together, columns from the first source table are combined with columns from the second source table—in the same row. So, each row in the resultant table contains columns from both tables.
- Unions combine rows. Rows of data from the first source table are combined with rows of data from the second source table into a single table. Each row in the resultant table is from one source table or another.
Normalization
Normalization focuses on cleaning the database of unused data and reducing redundancy and inconsistency.
Data coming from transactional systems, for example, where a number of insert, update, and delete operations are performed on an ongoing basis, are highly normalized.
Denormalization
Denormalization is used to combine data from multiple tables into a single table so that it can be queried faster.
For example, normalized data coming from transactional systems is typically denormalized before running queries for reporting and analysis. Another transformation type is Cleaning.
Cleaning
Cleaning tasks are actions that fix irregularities in data in order to produce a credible and accurate analysis.
The first step in the data cleaning workflow is to detect the different types of issues and errors that your dataset may have. You can use scripts and tools that allow you to define specific rules and constraints and validate your data against these rules and constraints. You can also use data profiling and data visualization tools for inspection.
Data Profiling
Data profiling helps you inspect the source data to understand the structure, content, and interrelationships in your data. It uncovers anomalies and data quality issues.
For example, blank or null values, duplicate data, or whether the value of a field falls within the expected range.
Visualizing
Visualizing the data using statistical methods can help you to spot outliers. For example, plotting the average income in a demographic dataset can help you spot outliers. That brings us to the actual cleaning of the data.
Tools
- Excel Power Query / Spreadsheets and Add-ins
- OpenRefine - is an open-source that allows you to import and export data in a wide variety of formats: TSV, CSV, XLS, XML, JSON
- Google DataPrep - cloud service that allows you to visually explore, clean, and prepare both structured and unstructured data- It suggests what every next step should be, and detects schemas, data types, and anomalies.
- Watson StudioIBM Refinery - allows you to discover, cleanse, and transform data with built-in operations
- Trifacta Wrangler - cloud based service famous for collaboration
- Python - Has a large number of libraries to process data: Jypyter Notebook, Numpy, Pandas
- R - Offers a large number of packages Dplyr, Data.table, Jsonlite…
DataOps Methodology
Enable an organization to utilize a repeatable process to build and deploy analytics and data pipelines. Successful implementation of this methodology allows an organization to know, trust, and use data to drive value.
It ensures that the data used in problem-solving and decision making is relevant, reliable, and traceable and improves the probability of achieving desired business outcomes. And it does so by tackling the challenges associated with inefficiencies in accessing, preparing, integrating, and making data available.
In a nutshell, the DataOps Methodology consists of three main phases:
- The Establish DataOps Phase provides guidance on how to set up the organization for success in managing data.
- The Iterate DataOps Phase delivers the data for one defined sprint.
- The Improve DataOps Phase ensures learnings from each sprint is channeled back to continually improve the DataOps process.
The figure below presents a high-level overview of these phases and the key activities within each of these phases.
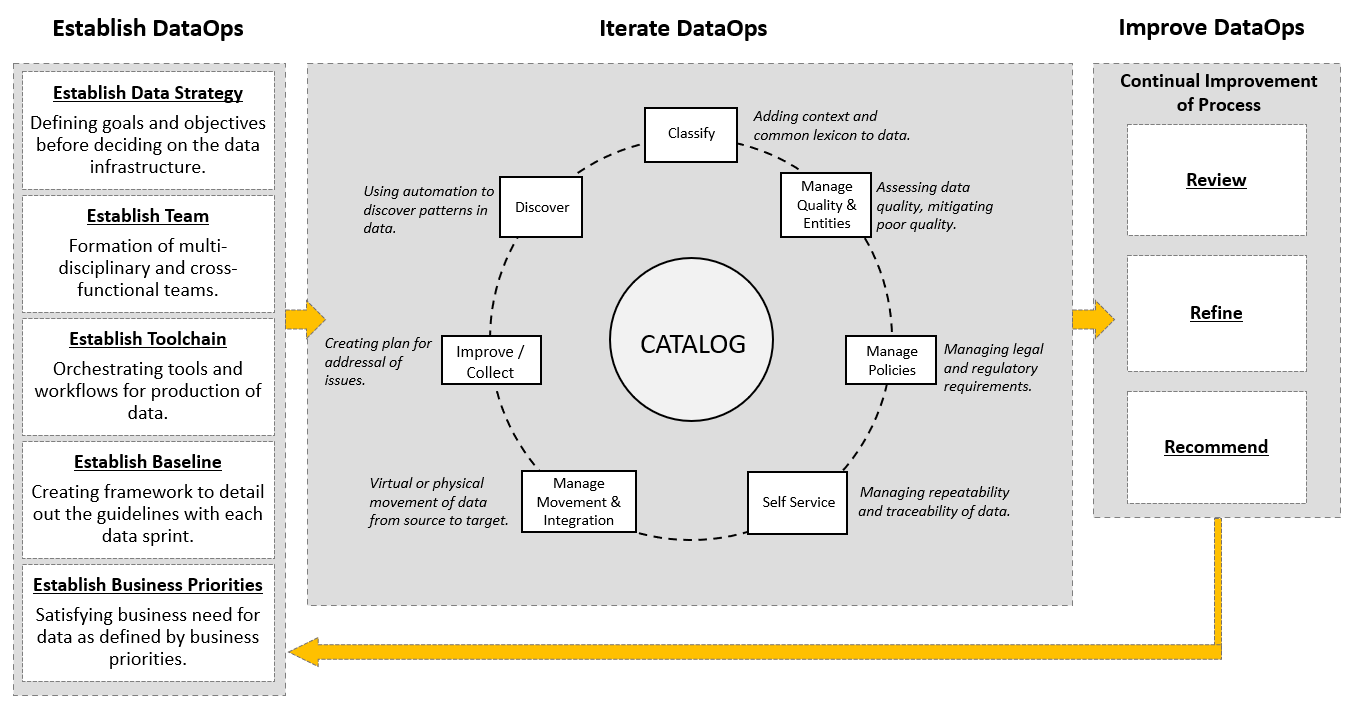
Benefits of DataOps
Adopting the DataOps methodology helps organizations to organize their data and make it more trusted and secure. Using the DataOps methodology, organizations can:
- Automate metadata management and catalog data assets, making them easy to access.
- Trace data lineage to establish its credibility and for compliance and audit purposes.
- Automate workflows and jobs in the data lifecycle to ensure data integrity, relevancy, and security.
- Streamline the workflow and processes to ensure data access and delivery needs can be met at optimal speed.
- Ensure a business-ready data pipeline that is always available for all data consumers and business stakeholders.
- Build a data-driven culture in the organization through automation, data quality, and governance.
Governance & Complicance
Governance
Data Governance is a collection of principles, practices, and processes that help maintain the security, privacy, and integrity of data through its lifecycle.
Personal Information and Sensitive Personal Information, that is, data that can be traced back to an individual or can be used to identify or cause harm to an individual, needs to be protected through governance regulations.
General Data Protection Regulation, or GDPR, is one such regulation that protects the personal data and privacy of EU citizens for transactions that occur within EU member states. Regulations, such as HIPAA (Health Insurance Portability and Accountability Act) for Healthcare, PCI DSS (Payment Card Industry Data Security Standard) for retail, and SOX (Sarbanes Oxley) for financial data are some of the industry-specific regulations.
Data Acquisition
In the Data Acquisition stage, you need to establish
- What data needs to be collected and the contracts and consent that give you a legal basis for procuring this data.
- The intended use of this data, published as a privacy policy and communicated internally and with individuals whose data is being collected.
- The amount of data you need to meet your defined purposes. For example, does the email address meet your purpose, or do you also need to have the phone numbers and pin codes?
Data Processing
In the Data Processing stage, you will be required to establish
- The details of how you are going to process personal data.
- And your legal basis for the processing of personal data, such as a contract or consent.
Data Storage
In the Data Storage stage, you will be required to establish
- Where the data will be stored, including specific measures that will be taken to prevent internal and external security breaches.
Data Sharing
In the Data Sharing stage, you will establish
- Which third-party vendors in your supply chain may have access to the data you are collecting.
- as well how will you hold them contractually accountable to the same regulations you are liable for.
Data Retention
In the Data Retention and Disposal stages, you will be required to
- establish what policies and processes you will follow for the retention and deletion of personal data after a designated time
- and how will you ensure that in the case of data deletion, it will be removed from all locations, including third-party systems?
At each of these stages, you will be required to maintain an auditable trail of personal data acquisition, processing, storage, access, retention, and deletion.
Compliance
Compliance covers the processes and procedures through which an organization adheres to regulations and conducts its operations in a legal and ethical manner.
Compliance requires organizations to maintain an auditable trail of personal data through its lifecycle, which includes acquisition, processing, storage, sharing, retention, and disposal of data.
Now let’s look at some of the controls made available through different tools and technologies for ensuring compliance to governance regulations.
Authentication and Access Control
Today’s platforms offer layered authentication processes, such as a combination of passwords, tokens, and biometrics, to provide foolproof protection against unauthorized access of data.
- Authentication systems are designed to verify that you are who you say you are.
- Access control systems ensure that authorized users have access to resources, both systems and data, based on their user group and role.
Encryption
- Using encryption, data is converted to an encoded format that can only be legible once it is decrypted via a secure key.
- Encryption of data is available both for data at rest, as it resides in the storage systems, and data in transit, as it moves through browsers, services, applications, and storage systems.
Data Masking
Data Masking provides anonymization of data for downstream processing and pseudonymization of data.
- Using Anonymization, the presentation layer is abstracted without changing the data inthe database itself. For example, replacing characters with symbols when they are displayed on the screen.
- Pseudonymization of data is a de-identification process where personally identifiable information is replaced with artificial identifiers so that a data set cannot be traced back to an individual’s identity—for example, replacing the name with a random value from the names dictionary.
Monitoring and Alerting functionalities
Security monitoring helps to proactively monitor, track, and react to security violations across infrastructure, applications, and platforms.
- Monitoring systems also provide detailed audit reports that track access and other operations on the data.
- Alerting functionalities flag security breaches as they occur so that immediate remedial actions can be triggered. The alerts are based on the severity and urgency level of the breach, which is pre-defined in the system.
Data Erasure
Data erasure is a software-based method of permanently clearing data from a system by overwriting. This is different from a simple deletion of data since deleted data can still be retrieved.