ETL vs ELT Basics
ETL
Extract, Transform, and Load refers to the process of curating data from multiple sources, conforming it to a unified data format or structure, and loading the transformed data into its new environment.
Extract
Data extraction is the first stage of the ETL process, where data is acquired from various source systems.
- the data may be completely raw, such as sensor data from IoT devices
- perhaps it is unstructured data from scanned medical documents or company emails
- it may be streaming data coming from a social media network
- near real-time stock market buy/sell transactions
- it may come from existing enterprise databases and data warehouses
- normally this is an automated process and could be such as web scraping, using APIs to connect to data and query it
- source data can be static, such as a data archive (in which case the extraction could be done in a batch process)
- could be dynamic/streaming live from many locations (weather data, social network feeds, IoT devices…)
Techniques
- OCR - Optical Character Recognition, is used to interpret and digitize text scanned from paper documents
- ADC - to digitize analog audio recordings and signals
- CC - charge couple devices that capture and digitize images
- Opinions, questionnaires, vital statistical data
- Cookies, user logs, and other methods to track human or system behavior
- Web scraping
- APIs for extracting data from all online data repositories and feeds
- SQL for querying relational databases
- NoSQL for querying document, key value, graph, or other non-structured data repositories
- Edge computing to reduce data volume by extracting raw data we are interested in, rather than transmitting all the data collected
Transform
The transformation stage (wrangle stage) is where rules and processes are applied to the data to prepare it for loading into the target system.
This is normally done in an intermediate working environment called a “staging area.” Here, the data are cleaned to ensure reliability and conformed to ensure compatibility with the target system and in the intended use cases.
Transformation is about formatting the data to suit the application
Many other transformations may be applied, including:
- Typing: casting data to appropriate types: float, integer, string…
- Data structuring: converting data format to another, such as JSON, XML, or CSV to database tables
- Anonymizing and encrypting to ensure privacy and security
- Cleaning: fixing any errors or missing values
- Filtering: selecting only what is needed
- Joining: merging disparate data sources
- Normalizing: converting data to common units
- Data Structuring: converting one data format to another, such as JSON, XML, or CSV to database tables
- Feature Engineering: creating KPIs for dashboards or machine learning
- Anonymizing and Encrypting: ensuring privacy and security
- Sorting: ordering the data to improve search performance
- Aggregating: summarizing granular data
Schema-on-write
The conventional approach used in ETL pipelines, where the data must be conformed to a defined schema prior to loading to a destination, such as a relational database.
The idea is to have the data consistently structured for stability and for making subsequent queries much faster. But this comes at the cost of limiting the versatility of the data. Once you filter, group, aggregate and …. the data you’ve already reached a stage beyond its original raw state.
Load
The load phase is all about writing the transformed data to a target system its new environment.
- The system can be as simple as a comma-separated file, which is essentially just a table of data like an Excel spreadsheet
- A database, which may be part of a much more elaborate system, such as a data warehouse, a data mart, data lake, or some other unified, centralized data store
- The purpose of loading is to make the data available for analysis, modeling, and data-driven decision making by business analysts, managers, executives, data scientists, and users at all levels of the enterprise
In most cases, as data is being loaded into a database, the constraints defined by its schema must be satisfied for the workflow to run successfully. Thus, such requirements imposed on the loading phase help ensure overall data quality.
- The schema - a set of rules called integrity constraints, includes rules such as
- uniqueness
- referential integrity
- mandatory fields
Full loading
Full loading is used when you want to start tracking transactions in a new data warehouse or when you want to load an initial history into a database.
To reiterate, there is no existing content when you use full loading.
Incremental Loading
After full loading is complete, you can use incremental loading to insert data that has changed since the previous loading.
With incremental loading strategy, data is appended in the database and not overwritten.
It is useful for accumulating transaction history. You can categorize incremental loading into stream loading and batch loading, depending on the volume and velocity of data.
Stream loading
Stream loading is used when the data is to be loaded real time. Stream loading refers to continuous data updates performed in the data warehouse or other storage systems as new data arrives.
It is usually triggered by events, such as real-time data from sensors, like thermostat or motion sensors, social media feed, and IoT devices, and measures, such as data size when a certain amount of data is collected, or threshold values, or when a user requests data, such as online videos, music, or web pages.
Batch loading
Batch loading refers to periodic updates made/pushed to the data in the data warehouse or other storage systems, such as daily updates, hourly updates, or weekly updates. Batch data can be scheduled. Batch loading is used when it’s efficient and effective to load data in batches.
Some examples include Windows Task Scheduler, Cron jobs in Linux, and daily stock update.
Push loading
A push method is used when the source pushes data into the data warehouse or other storage. While push method can be used for batch loading, it is most suited for stream loading involving real-time data.
Pull loading
A pull method is used when the data warehouse pulls the data from the source by subscribing to receive the data. It is useful for scheduled transactions and batch loading. Loading can be serial or parallel.
Serial loading
Serial loading is when the data is copied sequentially, one after the other. This is how data loads in the data warehouse by default.
Parallel loading
You can use parallel loading when you need to load data from different sources parallelly or to split data from one source into chunks and load them parallelly.
- When compared with serial loading, parallel loading is a faster and optimized approach.
- Parallel loading can be employed on multiple data streams to boost loading efficiency, particularly when the data is big or has to travel long distances.
- Similarly, by splitting a single file into smaller chunks, the chunks can be loaded simultaneously.
Pipelines
Pipelines are meant to facilitate the processing of data, or digitizing analog media and moving it from OLTP systems to OLAP systems
OLTP & OLAP
- Online Transaction Processing systems (OLTP) don’t save historical data. ETL processes capture the transaction history and prepare it for
- Subsequent analysis in an Online Analytical Processing systems (OLAP), dashboards…
ELT
Similar to ETL, it is a specific automated data pipeline engineering methodology. It is similar to ETL but the order in which the stages are performed varies. ELT is an evolution of ETL
- Data is Extracted and loaded as is into its new environment where modern analytic tools can be used directly
- It is more dynamic than ETL
- It is used more often in the big data high performance computing realms with cases including:
- massive swings and scale associated with big data
- calculating real-time analytics on streaming bid data
- bringing together data sources that are distributed around the globe
- Moving data is a bigger bottle neck than processing it, the less you move it the better
Why is ELT emerging
- Cloud computing emergence, and their focus on big data. Their ability to handle large amounts of asynchronous data
- Cloud computing resources are unlimited and can be scaled for demand
- On demand costs are lower than fixed on-premises hardware
- You can separate transforming from moving which eliminates data loss because you’re moving raw data as is.
Schema-on-read
Schema-on-read relates to the modern ELT approach, where the schema is applied to the raw data after reading it from the raw data storage. This approach is versatile since it can obtain multiple views of the same source data using ad hoc schemas.
Users potentially have access to more data, since it does not need to go through a rigorous preprocessing step. Whether intentional or accidental, there are many ways in which information can be lost in transformation. We can visualize this loss as follows:
- Raw data is normally much bigger than transformed data.
- Since data usually contains noise and redundancy, the information content of data as a proper subset of the data.
- Correspondingly, we can see that shrinking the data volume can also mean shrinking the information content.
For ETL processes, any lost information may or may not be recoverable, whereas with ELT, all the original information content is left intact because the data is simply copied over as is.
ETL vs ELT
So what are the key differences between the two aside from the obvious:
| Process | ETL | ELT |
|---|---|---|
| Transformation | within data pipeline | in the destination environment |
| Flexibility | rigid, engineered to user specs | flexible, user builds their own |
| Big Data | relational data | structured and unstructured |
| Location | on-premise, scalability restraints | scalable on demand in the cloud |
| Time-to-insight | Teams wait on others to specify and develop | self-serve, interactive anlytics in real-time |
| Intermediate storage | Typical staging areas (data lakes) for raw data where processes are run prior to loading. A private staging area | staging area is a data lake where you can manipulate raw data shared with everyone |
| Pain points | Lengthy time-to-insight, challenges of Big Data, siloed information | Solves those issues |
| Source & destination databases are | different | same |
| Capable of handling [ ] data transformation | complex | simple |
| Data size it can handle | small relative to ELT | huge |
| Latency | high | low |
| Type of data | static, archived | IoT, live sensor data |
| Processing type | MapReduce | Spark Streaming |
| Activity type | scheduled activity | realtime activity |
ETL Workflow
Generally, an ETL workflow is a well thought out process that is carefully engineered to meet technical and end-user requirements.
Traditionally, the overall accuracy of the ETL workflow has been a more important requirement than speed, although efficiency is usually an important factor in minimizing resource costs.
To boost efficiency, data is fed through a data pipeline in smaller packets. While one packet is being extracted, an earlier packet is being transformed, and another is being loaded. In this way, data can keep moving through the workflow without interruption. Any remaining bottlenecks within the pipeline can often be handled by parallelizing slower tasks.
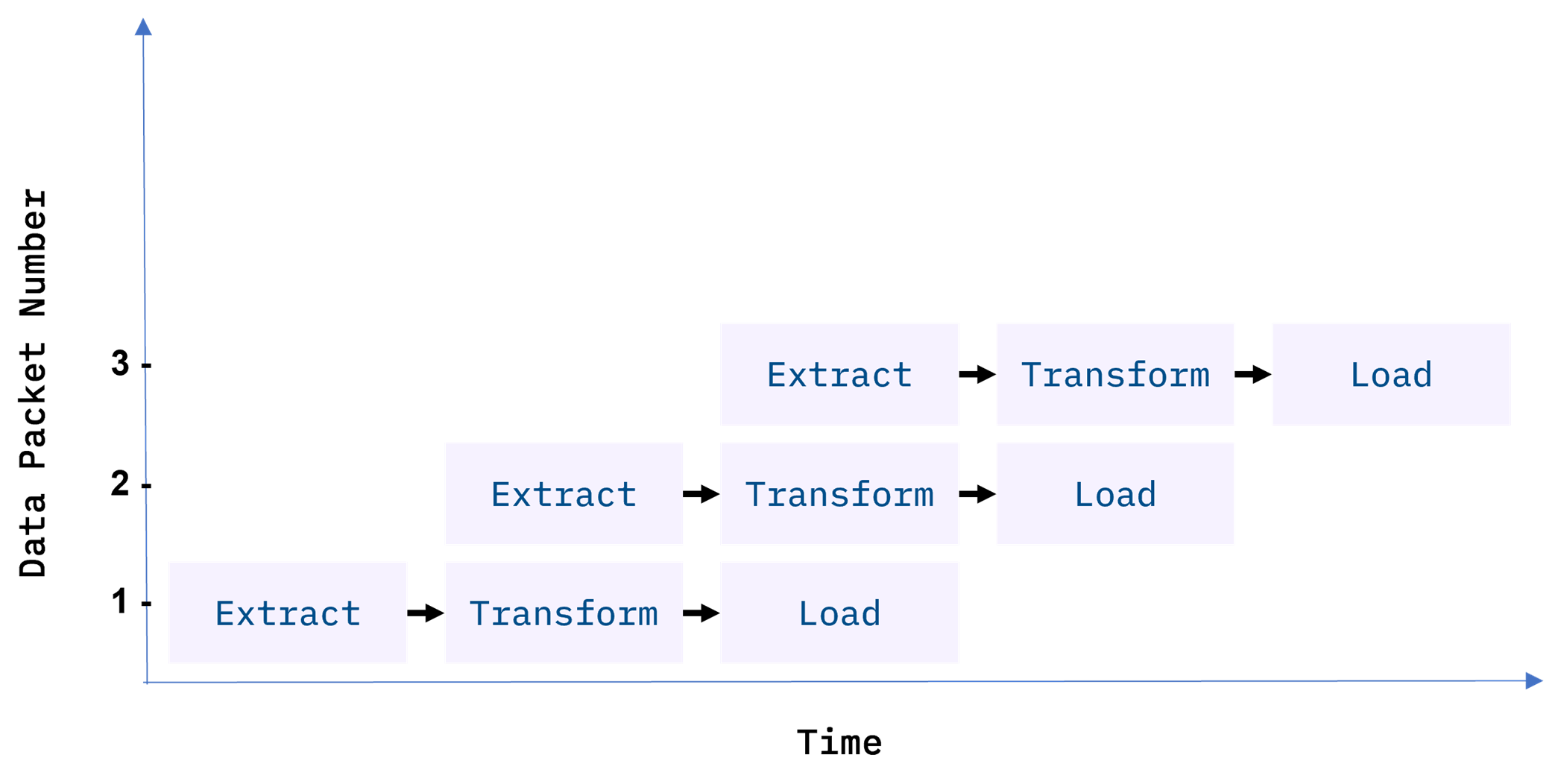
With conventional ETL pipelines, data is processed in batches, usually on a repeating schedule that ranges from hours to days apart. For example, records accumulating in an Online Transaction Processing System (OLTP) can be moved as a daily batch process to one or more Online Analytics Processing (OLAP) systems where subsequent analysis of large volumes of historical data is carried out.
Batch processing intervals need not be periodic and can be triggered by events, such as
- when the source data reaches a certain size, or
- when an event of interest occurs and is detected by a system, such as an intruder alert, or
- on-demand, with web apps such as music or video streaming services
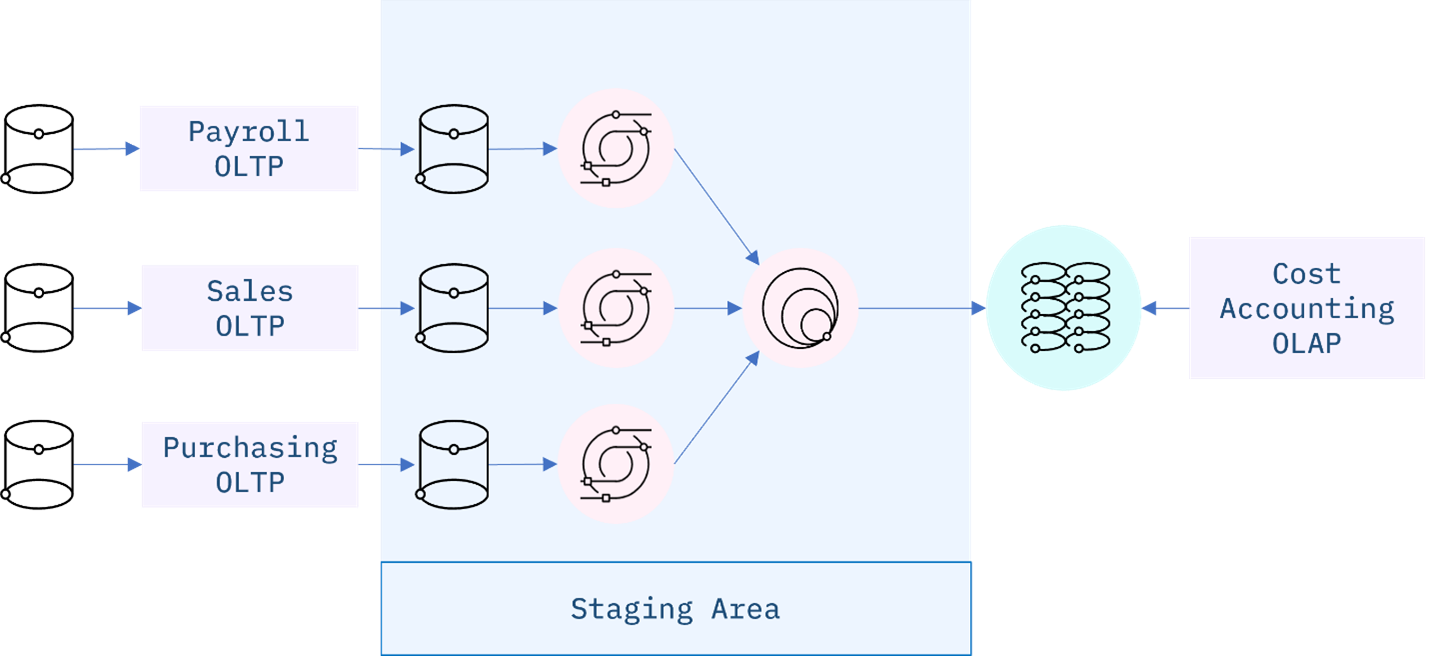
Staging Areas
ETL pipelines use staging areas to integrate data from disparate and usually siloed systems within the enterprise.
These systems can be from different vendors, locations, and divisions of the company, which can add significant operational complexity. As an example, a cost accounting OLAP system might retrieve data from distinct OLTP systems utilized by separate payroll, sales, and purchasing departments.
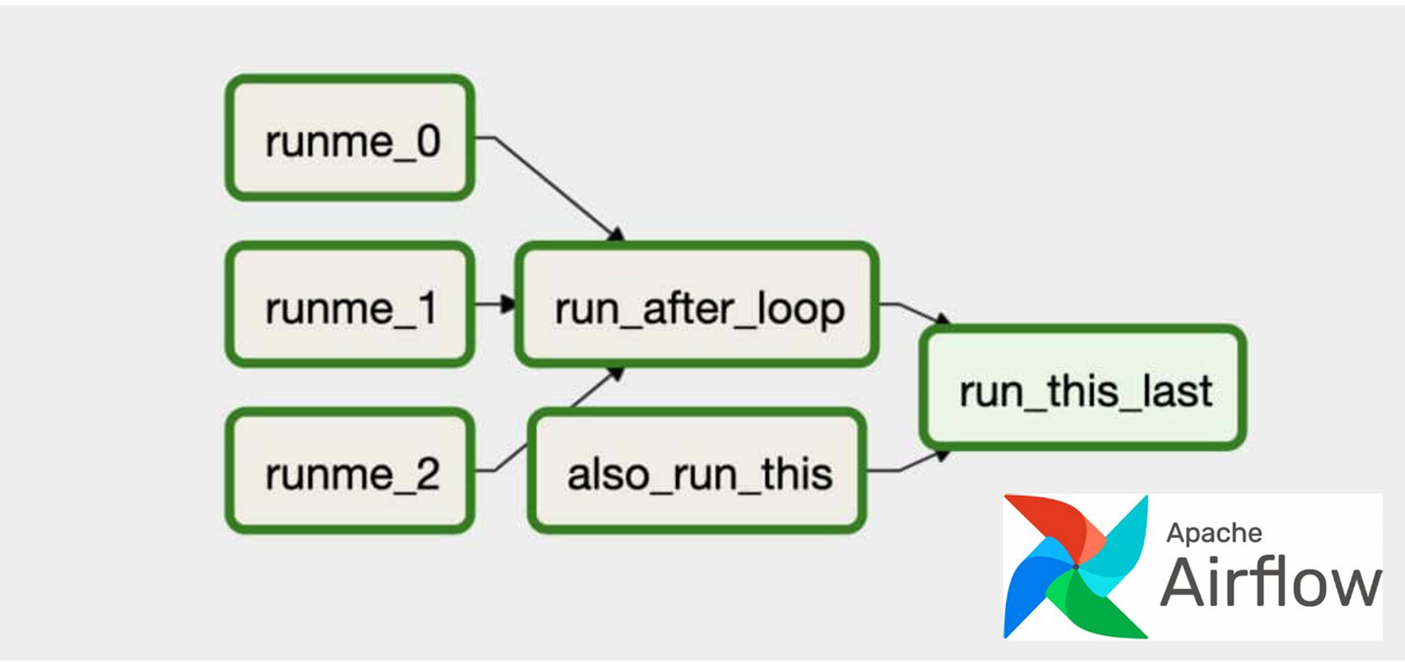
Airflow & ETL Workflow
ETL workflows can involve considerable complexity. By breaking down the details of the workflow into individual tasks and dependencies between those tasks, one can gain better control over that complexity. Workflow orchestration tools such as Apache Airflow do just that.
Airflow represents your workflow as a directed acyclic graph (DAG). A simple example of an Airflow DAG is illustrated below. Airflow tasks can be expressed using predefined templates, called operators.
Popular operators include
- Bash operators, for running Bash code, and
- Python operators for running Python code, which makes them extremely versatile for deploying ETL pipelines and many other kinds of workflows into production.
Popular ETL Tools
There are many ETL tools available today. Modern enterprise grade ETL tools will typically include the following features:
- Automation: Fully automated pipelines
- Ease of use: ETL rule recommendations
- Drag-and-drop interface: “no-code” rules and data flows
- Transformation support: Assistance with complex calculations
- Security and Compliance: Data encryption and HIPAA, GDPR compliance
Some well-known ETL tools are listed below, along with some of their key features. Both commercial and open-source tools are included in the list.
Talend Open Studio
Open-source data pipeline development and deployment platform.
- Talent Open Studio supports big data migration, data warehousing, and profiling, and it includes
- collaboration, monitoring and scheduling capabilities.
- It also has an interactive drag-and-drop GUI, which allows you to create ETL pipelines.
- There is no need to write code as Java code is automatically generated.
- It also connects to many data warehouses such as Google Sheets, RDBMS, IBM, DB2, and Oracle.
AWS Glue
An Enterprise tools: AWS Glue is a fully managed ETL service that makes it easy for you to prepare and load your data for analytics.
- Glue crawls your data sources to discover data formats and suggests schemas to store your data and you can quickly create and run an ETL job using the AWS console.
IBM InfoSphere DataStage
IBM InfoSphere DataStage is a data integration tool for designing, developing, and running both ETL and ELT pipelines.
InfoSphere DataStage is the data integration component of IBM InfoSphere information server.
- Like many other platforms, it also provides a drag-and-drop framework for developing workflows.
- InfoSphere DataStage also uses parallel processing and enterprise connectivity to provide a truly scalable platform.
IBM Streams
- IBM Streams is a streaming data pipeline technology, which enables you to build real time analytical applications using
- the Streams processing language or SPL, plus Java, Python, or C++.
- You can use it to blend data in motion with data at rest to deliver continuous intelligence in real time.
- Streams powers a stream analytics service that allows you to ingest and analyze millions of events per second with sub-millisecond latency,
- and IBM Streams comes packaged with IBM Stream Flows,
- a tool which allows you to drag and drop operators onto a canvas and modify parameters from built-in settings panels.
Alteryx
Alteryx is also a highly versatile self-service data analytics platform with multiple products.
- It gives you drag-and-drop accessibility to built in ETL tools,
- and you don’t need to know SQL or programming to create and maintain a complex data pipeline.
Apache Airflow and Python
Apache Airflow, another package based on the Python programming language is
- a highly versatile and well-known example of an open-source configuration as code data pipeline platform.
- Apache Airflow was open-sourced by Airbnb and was created to programmatically author, schedule, and monitor data pipeline workflows.
- It was designed to be scalable and can handle an arbitrary number of parallel compute nodes,
- and Airflow integrates with most Cloud platforms, including AWS, IBM, Google Cloud, and Microsoft Azure.
Pandas Python Library
Python, along with the Pandas library is a very popular and highly versatile programming environment for building data pipelines.
- Pandas uses a data structure called a data frame to handle Excel or CSV-style tabular data.
- It’s a great tool for prototyping ETL pipelines and for exploratory data analysis but
- it can be challenging to scale to big data since data frame manipulations must be carried out in memory.
Libraries with similar data frame APIs include Dask, Vaex, and Apache Spark, which can all help you to scale up to big data. For scalability, consider SQL-like alternatives to data frame APIs, such as PostgreSQL.
Panoply
Panoply is another enterprise solution, but its focus is on ELT rather than ETL.
- It handles data connection and integration without code and
- comes with SQL functionality so you can generate views of your data.
- This frees your time to focus on data analysis, rather than optimizing your data pipeline.
- Panoply also integrates with many dashboard and BI tools, including Tableau and Power BI.