Data Pipeline
Definition
- Series of connected processes
- Pipelines are specified as dependencies between tasks
- The output of one process is the input of the next
- Any system which ETLs data
- Our focus is on software-driven processes: commands, programs and threads
- Bash ‘pipe’ command in Linux can be used to connect such processes together
Purpose
We can think of data flowing through a pipeline in the form of data packets.
- Move data from one place or form to another
- A term which we will use to broadly refer to units of data is Packets
- Packets can range in size from a single record or event to large collections of data.
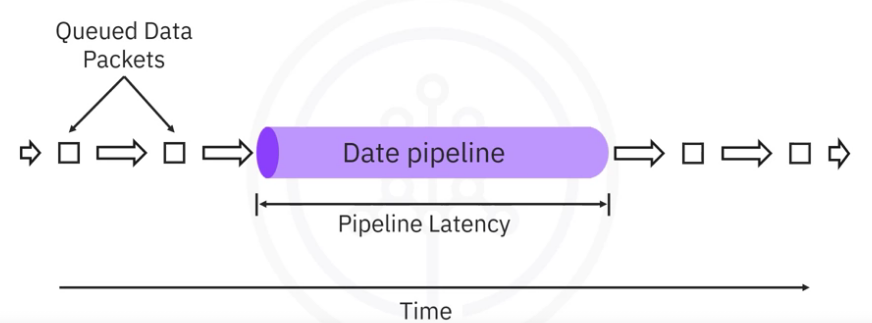
- Here we have data packets queued for ingestion to the pipeline.
- The length of the data pipeline represents the time it takes for a single packet to traverse the pipeline - throughput
- The arrows between packets represent the throughput delays or the times between successive packet arrivals - latency
You have just been introduced to two key performance considerations regarding data pipelines.
Latency
Latency is the total time it takes for a single packet of data to pass through the pipeline.
- Equivalently, latency is the sum of the individual time spent during each processing stage within the pipeline.
- Thus, overall latency is limited by the slowest process in the pipeline.
For example, no matter how fast your internet service is, the time it takes to load a web page will be decided by the server speed.
Throughput
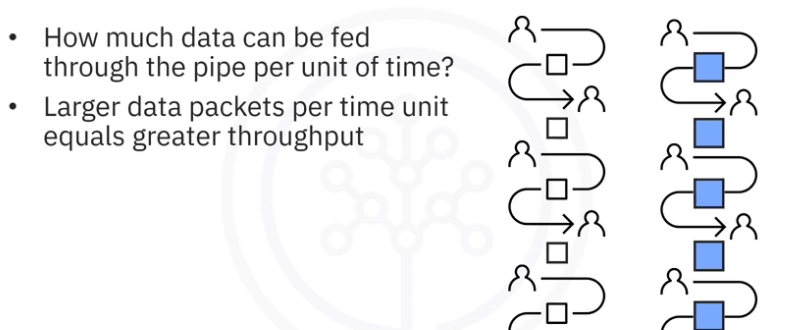
Refers to how much data can be fed through the pipeline per unit of time.
- Processing larger packets per unit of time increases throughput.
- Using the example of having a chain of friends passing boxes from one to another, we can see in the right image within limits, that passing bigger boxes can increase productivity.
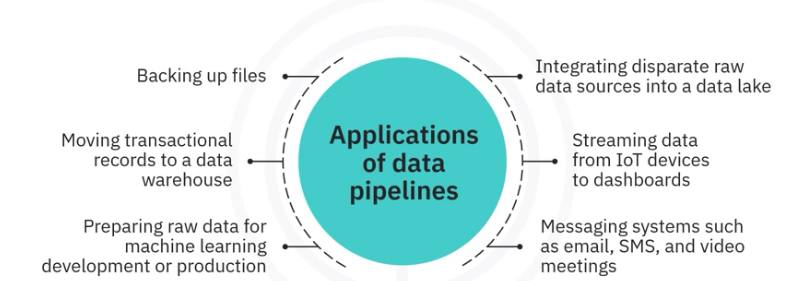
Use cases
Let’s list a few of the applications of data pipelines from the multitude of use cases.
Processes
Stages of DPP
Typical stages of Data Pipeline Processes - DPP are Data:
Extraction
Ingestion
Transformation
Loading
A mechanism for scheduling or triggering jobs to run
The DP needs to be monitored to ensure data integrity. Some key monitoring considerations include:
- latency
- throughput demand
- errors and failures caused by network overloading and failures at the source or destination
- utilization rates, or how fully the pipelines resources are being utilized
- a system for logging events and alerting administrators when failures occur
Maintenance and optimization:
- Ideally at the moment one stage has completed its process on a packet of data, the next packet in the queue would be available to it just in time.
- In that case, the stage is never left to idle while the pipeline is operating and there are no upstream bottlenecks.
- Extending this notion to all stages of the pipeline implies that all stages should take the same amount of time to process a packet.
- This means that there are no bottlenecks and we can say that the entire pipeline has been load balanced.
- One option is to parallelized the bottleneck area of a pipeline
- Pipeline that are parallelized are called dynamic or nonlinear as opposed to static (or serial pipelines) ones that are not adjusted
Stage synchronization
- Further synchronization between stages is possible and a typical solution is to include input and output buffers or I/O buffers as needed to smooth out the flow of data
- I/O buffer is a holding area for data placed between processing stages having different or varying delays.
- Buffers can also be used to regulate the output of stages having variable processing rates and thus may be used to improve throughput.
- Single input and output buffers are also used to distribute and gather loads on parallelized stages.
Batch vs Streaming DP
Batch
Batch data pipelines are used when
- Data sets need to be extracted and operated on as one big unit.
- Batch processes typically operate periodically on a fixed schedule, ranging from hours to weeks apart.
- They can also be initiated based on triggers, such as when the source data reaches a certain size.
- Batch processes are appropriate for cases which don’t depend on recency of data.
- Typically, batch data pipelines are employed when accuracy is critical, but competitive, mission-critical streaming technologies are rapidly maturing.
- Use cases examples
Streaming
Streaming data pipelines are designed to
- Ingest packets of information, such as individual credit card transactions or social media activities, one by one, in rapid succession.
- Stream processing is used when results are required with minimal latency, essentially in real time.
- With streaming pipelines, records or events are processed immediately as they occur.
- Event streams can also be appended to storage to build up a history for later use.
- Users, including other software systems, can publish or write and subscribe to or read event streams.
- Use cases examples:
- watching movies, listening to music or podcasta
- social media feeds, sentiment analysis
- fraud detection
- user behavior, targeted advertising
- stock market trading
- real-time pricing
- recommended systems
Micro-batch
By decreasing the batch size and increasing the refresh rate of individual batch processes, you can achieve near real-time processing.
- Using micro-batches may also help with load balancing, leading to lower overall latency.
- Useful when only very short windows of data are required for transformations.
Batch vs Stream
The use case differences between batch and stream processing come down to a trade-off between accuracy and latency requirements. If you require low latency, your tolerance for faults likely has to increase.
- With batch processing, for example,
- data can be cleaned,
- and thus you can get higher-quality output,
- but this comes at the cost of increased latency.
Lambda Architecture
A Lambda architecture is a hybrid architecture designed for handling big data. Lambda architectures combine batch and streaming data pipeline methods.
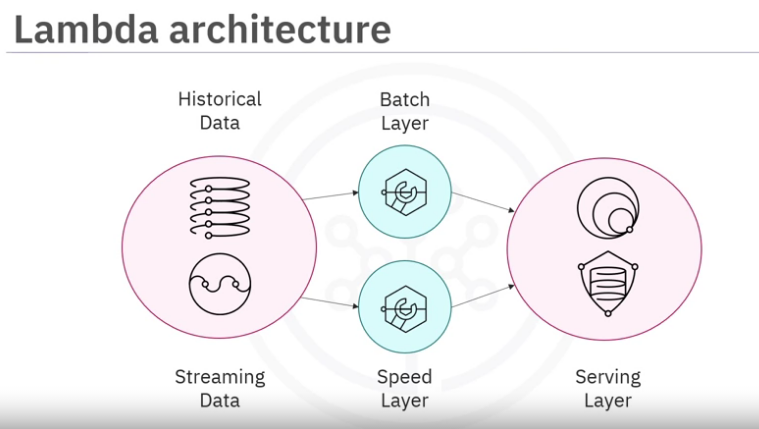
- Historical data is delivered in batches to the batch layer,
- and real-time data is streamed to a speed layer.
- These two layers are then integrated in the serving layer.
- The data stream is used to fill in the latency gap caused by the processing in the batch layer.
Lambda can be used in cases where access to earlier data is required, but speed is also important.
A downside to this approach is the complexity involved in the design. You usually choose a Lambda architecture when you are aiming for accuracy and speed.