Big Data Basics
As we get immersed in this tech age, data is collected about us. Everything we do is tracked, stored, some is marinated and never used, and some is used to annoy us, while some is used to make false predictions about the future, and that leaves a part that’s actually useful.
So how do we find that useful gem in a pile of data? Well they defined the pile as Big Data along with several elements that make up its definition:
- Velocity - speed at which data accumulates
- Volume - amount, scale of data being collected/generated
- Variety - the diversity of the data, its type, sources, structure…
- Veracity - the quality and origin of data, and its conformity to facts and accuracy
- Value - what benefit can we extract from the data
Processing
Big Data processing techologies provide ways to work with large set of structured, semi-structured, and unstructured data so that value can be derived from it. We already know that
- NoSQL and
- Data Lakes are used to store Big Data
We will talk about 3 open source technologies and the roles they play in bid data analytics:
- Apache Hadoop
- Apache Hive
- Apache Spark
| Technology | Role |
|---|---|
| Hadoop | Collection of tools that provides distributed storage and processing of bid data |
| Hive | Data Warehouse for data query & analysis built on top of Hadoop |
| Spark | Distributed data analytics framework designed to perform complex data analytics in real-time |
Mapreduce
A programming model for processing large data sets. Think of it as an API, an algorithm or a way of breaking up data sets and processing them in a distributed manner.. It offers a way to horizontally scale data analysis problems. It consists of a mapper and a reducer. Google invented and first used it for web crawling, page rank, Yahoo, Ebay, Amazon, Facebook (which contributed Hive)
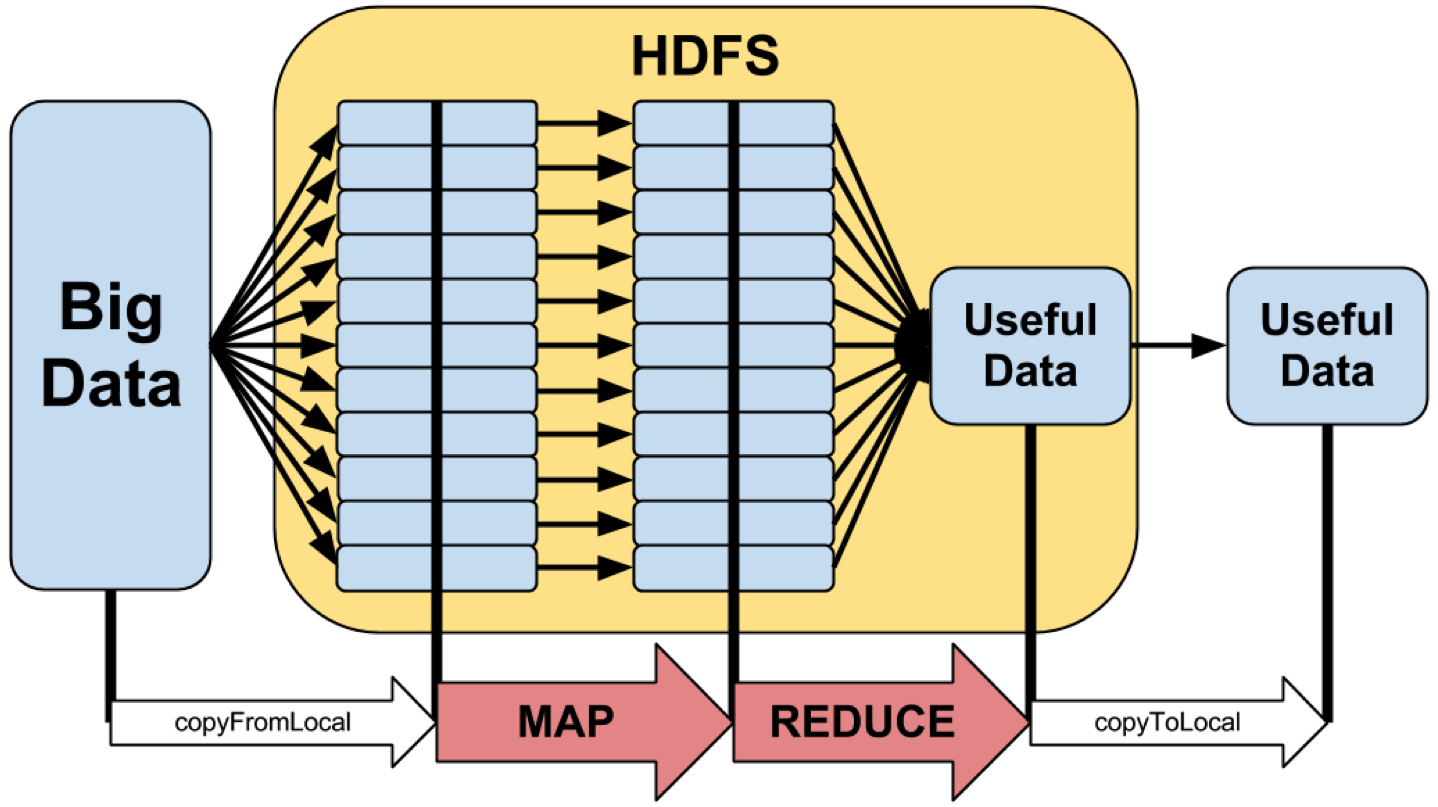
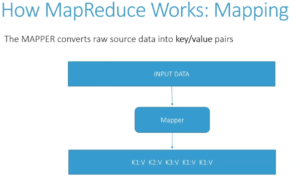
Mapper
Mapper is a function that parses source data and maps values to unique keys, so it extracts the information you care about from your data set and organizes it for you. Various parts of your data may go to different mappers which can process them in parallel on different computers. So for example
- If we use the movie lens data set and we want to see how many movies did each user rated
- In other words, we want to extract each unique user, or The KEY = User ID – For each unique UserID we want to find out the movies they rated. Because each user could have rated many movies
- And Map each Unique ID=KEY to the Movie ID value
- So the Mapper would provide us with the Values(MovieID) for Each Key(UserID)
- Here is the outcome which is the job of the mapper – which is to extract and organize what we care about. Kinda like a sort and grouping in python, so what it does automatically is group and sort the mapped data and we end up with this before it is sent to the Reducer

- So now it has consolidated all of those values together and then it sends each key to the reducer along with a function or an order of what to do with the keys, in this case we want to find out how many movies each user has rated so we just issue a function LEN() with would be the length of each key. So see below what the Reducer will output
Reducer
Processes all the values for a given key. So after the mapper is done, all the values for each key are sent to a reducers which then processes all that information for each key.

Horizontal Scaling
Its programming model lends itself well to distributing it throughout multiple computers on a large cluster. So HS has unlimited upward potential while you can add as many computers as you want to a cluster, hundreds, thousands…. till you get the job done. It does take skills to make those computers to communicate with each other, it scales much more widely than vertical scaling would. So MapReduce offers a programming model for distributing the processing of a large data set among multiple computers
Vertical Scaling
VS would be if you just kept adding more resources to one computer so if the data analysis job is too large for one computer, you just keep adding more processors and memory and other resources on top of that computer till you are able to do the job.
Hadoop
Is a java-based open source framework software that manages applications that run on a cluster of computers (like MapReduce). It manages the cluster for you. It makes sure all your data is distributed and is where it is supposed to be. It provides distributed storage and processing of large datasets across clusters of computers.
- It offers HDFS (Hadoop Distributed File System) a storage system for big data
- Hadoop also manages all the communication between computers through a technology called YARN – see below.
- It also gives you fault-tolerance, so it not only allows you horizontal scaling, but the more computers you add the higher the probability that one will fail while processing a job.
- Hadoop can actually duplicate your data across multiple machines in your cluster and that way if one of your computers goes down you know which computer to to instead to retrieve the backup copy and continue the process as if nothing happened.
- You can incorporate emerging data formats, videos, audio, social media sentiment, along with structured, semi-structured, and unstructured data not traditionally used in data warehouses
- Provides real-time, self-service access for all stakeholders
- One of the four main components of Hadoop is Hadoop Distributed File System - HDFS
- Hadoop is intended for long sequential scans, therefore queries have a very high latency
HDFS
It’s the mechanism for sharing files across the cluster in a reliable manner. So if you have a large datasets, all your nodes on your computer cluster need to access that data somehow and then need to write the results someplace as well and that’s where HDFS comes into play.
- HDFS provides scalable and reliable big data storage by partitioning files over multiple nodes
- It splits large files across multiple computers, allowing parallel access to them. Computation can therefore run in parallel on each node where data is stored
- HDFS replicates these smaller pieces onto two additional servers by default, ensuring availability when a server fails
- It allows the Hadoop cluster to break up work into smaller chunks and run those jobs on all servers in the cluster for better scalability
- It also replicates file blocks on different nodes to prevent data loss, making it fault-tolerant
- It provides data locality, which means it moves the computation closer to the node on which the data resides. This is helpful and critical in large datasets because it minimizes network congestion and increases throughput.
- Other benefits include:
- Fast recovery from hardware failures, because it is built to detect faults and automatically recover
- Access to streaming data, because HDFS supports high data throughput rates
- Accommodation of large datasets, because HDFS can scale to hundreds of nodes, or computers in a single cluster.
- Portability, because HDFS is portable across multiple hardware platforms and compatible with a variety of underlying operating systems
Example
Consider a file that includes phone numbers for everyone in the United States; the numbers for people with last name starting with A might be stored on server 1, B on server 2, and so on.
With Hadoop, pieces of this phonebook would be stored across the cluster. To reconstruct the entire phonebook, your program would need the blocks from every server in the cluster.
Yarn
Communication between computers and keeps track of what information is where, and what information goes where and on which cluster and how they communicate with each other to coordinate their results.
Hive
Hive is an open-source data warehouse software for reading, writing, and managing large data set files that are stored directly in either HDFS or other data storage systems such as Apache HBase.
Hadoop is intended for long sequential scans and, because Hive is based on Hadoop, queries
have very high latency—which means Hive is less appropriate for applications that need very fast response times.
Hive is read-based, and therefore not suitable for transaction processing that typically involves a high percentage of write operations.
Hive is better suited for data warehousing tasks such as ETL, reporting, and data analysis and includes tools that enable easy access to data via SQL.
This brings us to Spark
Spark
Spark is a general-purpose data processing engine designed to extract and process large volumes of data for a wide range of applications, including Interactive Analytics, Streams Processing, Machine Learning, Data Integration, and ETL.
It takes advantage of in-memory processing to significantly increase the speed of computations
and spilling to disk only when memory is constrained.
Spark has interfaces for major programming languages, including Java, Scala, Python, R, and SQL.
It can run using its standalone clustering technology as well as on top of other infrastructures
such as Hadoop.
It can access data in a large variety of data sources, including HDFS and Hive, making it highly versatile.
The ability to process streaming data fast and perform complex analytics in real-time
is the key use case for Apache Spark.