pip3 install kafka-pythonOverview
Detailed information can be found on their documentation site.
Kafka is a distriburted ESP - Event Streaming Platform, it is used
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
It is used for two broad classes of application:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
Event Streaming
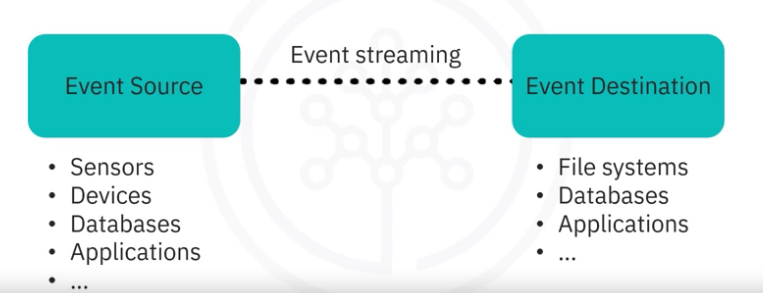
Technically speaking, event streaming is the practice of capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications in the form of streams of events; storing these event streams durably for later retrieval; manipulating, processing, and reacting to the event streams in real-time as well as retrospectively; and routing the event streams to different destination technologies as needed.
Event streaming thus ensures a continuous flow and interpretation of data from an Event Source to an Event Destination, so that the right information is at the right place, at the right time.
Event streaming is applied to a wide variety of use cases across a plethora of industries and organizations. Its many examples include:
- To process payments and financial transactions in real-time, such as in stock exchanges, banks, and insurances.
- To track and monitor cars, trucks, fleets, and shipments in real-time, such as in logistics and the automotive industry.
- To continuously capture and analyze sensor data from IoT devices or other equipment, such as in factories and wind parks.
- To collect and immediately react to customer interactions and orders, such as in retail, the hotel and travel industry, and mobile applications.
- To monitor patients in hospital care and predict changes in condition to ensure timely treatment in emergencies.
- To connect, store, and make available data produced by different divisions of a company.
- To serve as the foundation for data platforms, event-driven architectures, and microservices.
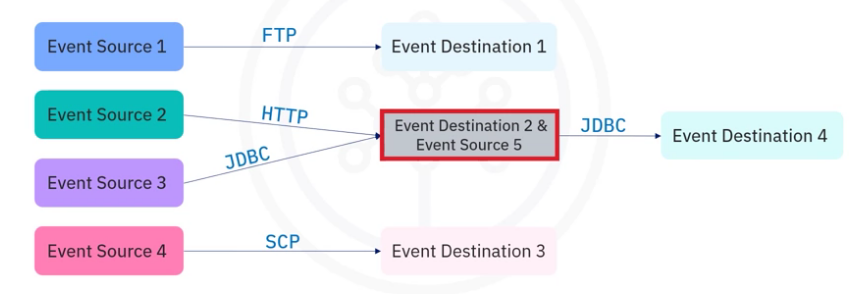
Event streaming could get complex with multiple sources and destinations, and with destinations acting as sources.
How it Works
Kafka is a distributed system consisting of servers and clients that communicate via a high-performance TCP network protocol. It can be deployed on bare-metal hardware, virtual machines, and containers in on-premise as well as cloud environments.
Servers
Kafka is run as a cluster of one or more servers that can span multiple datacenters or cloud regions. Some of these servers form the storage layer, called the brokers. Other servers run Kafka Connect to continuously import and export data as event streams to integrate Kafka with your existing systems such as relational databases as well as other Kafka clusters. To let you implement mission-critical use cases, a Kafka cluster is highly scalable and fault-tolerant: if any of its servers fails, the other servers will take over their work to ensure continuous operations without any data loss.
Clients
They allow you to write distributed applications and micro-services that read, write, and process streams of events in parallel, at scale, and in a fault-tolerant manner even in the case of network problems or machine failures. Kafka ships with some such clients included, which are augmented by dozens of clients provided by the Kafka community: clients are available for Java and Scala including the higher-level Kafka Streams library, for Go, Python, C/C++, and many other programming languages as well as REST APIs.
Concepts
- Kafka is run as a cluster on one or more servers
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp
Event
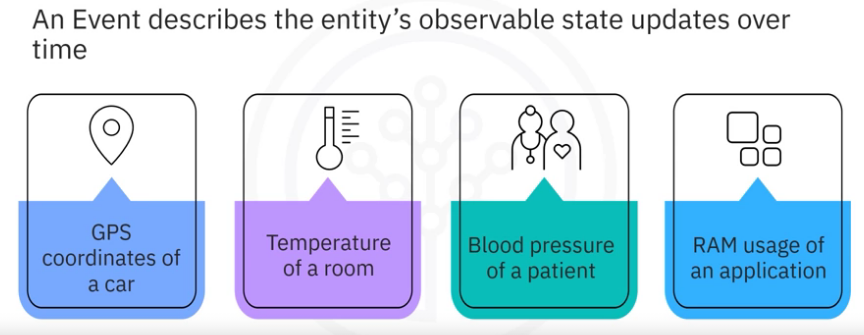
An event records the fact that “something happened” in the world or in your business. It is also called record or message in the documentation. When you read or write data to Kafka, you do this in the form of events. Conceptually, an event has a key, value, timestamp, and optional metadata headers (it might even include a primitive data type like a string).
Here’s an example event:
- Event key: “Alice”
- Event value: “Made a payment of $200 to Bob”
- Event timestamp: “Jun. 25, 2020 at 2:06 p.m.”
Producers & Consumers
Producers are those client applications that publish (write) events to Kafka, and
Consumers are those that subscribe to (read and process) these events.
In Kafka, producers and consumers are fully decoupled and agnostic of each other, which is a key design element to achieve the high scalability that Kafka is known for.
For example, producers never need to wait for consumers. Kafka provides various guarantees such as the ability to process events exactly-once.
Topics
Events are organized and durably stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder.
An example topic name could be “payments”.
- Topics in Kafka are always multi-producer and multi-subscriber: a topic can have zero, one, or many producers that write events to it, as well as zero, one, or many consumers that subscribe to these events.
- Events in a topic can be read as often as needed—unlike traditional messaging systems, events are not deleted after consumption. Instead, you define for how long Kafka should retain your events through a per-topic configuration setting, after which old events will be discarded.
- Kafka’s performance is effectively constant with respect to data size, so storing data for a long time is perfectly fine.
- Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time.
- When a new event is published to a topic, it is actually appended to one of the topic’s partitions.
- Events with the same event key (e.g., a customer or vehicle ID) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition’s events in exactly the same order as they were written.
- To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters, so that there are always multiple brokers that have a copy of the data just in case things go wrong, you want to do maintenance on the brokers, and so on.
- A common production setting is a replication factor of 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.

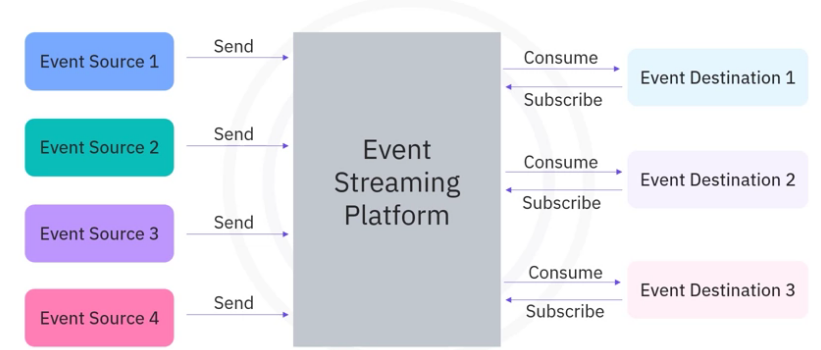
An ESP acts as a middle layer among various event sources and destinations and provides a unified interface for handling event-based ETL.
- All event sources only need to send events to an ESP instead of sending them to the individual event destination.
- Event destinations only need to subscribe to an ESP and just consume the event sent from the ESP instead of the individual event source.
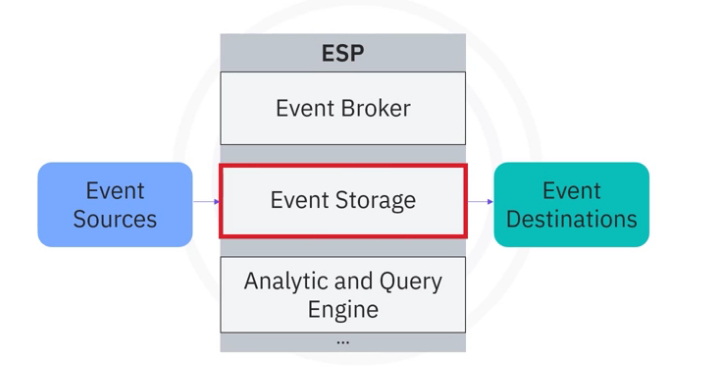
Different ESPs may have different architectures and components. Below we show you some common components included in most ESP systems.
- The first and foremost component is the event broker, which is designed to receive and consume events.
- The second common component of an ESP is event storage, which is used for storing events being received from event sources.
- Accordingly, event destinations do not need to synchronize with event sources, and stored events can be retrieved at will.
- The third common component is the analytic and query engine, which is used for querying and
- analyzing the stored events.
Components
Event Broker
Let’s have a look at the event broker, which is the core component of an ESP.
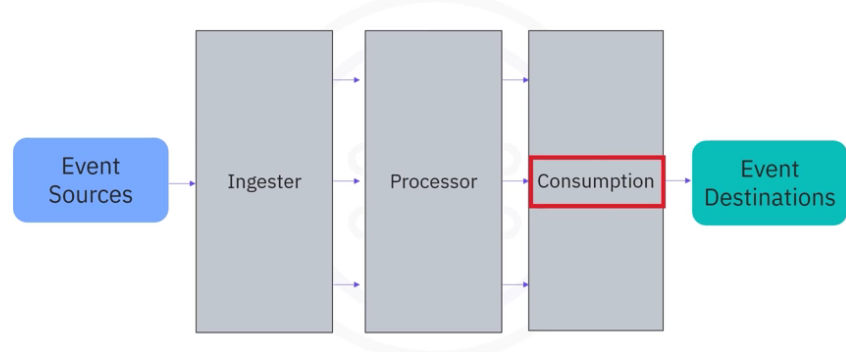
It normally contains three subcomponents ingester, processor, and consumption.
- The ingester is designed to efficiently receive events from various event sources.
- The processor performs operations on data such as serializing and deserializing, compressing and decompressing, encryption and decryption, and so on.
- The consumption component retrieves events from event storage and efficiently distributes them to subscribed event destinations.
A Kafka cluster contains one or many brokers. You may think of a Kafka broker as a
- dedicated server to receive, store, process, and distribute events.
- Brokers are synchronized and use KRaft controller nodes that use the consensus protocol to manage the Kafka metadata log that contains information about each change to the cluster metadata.
Topics
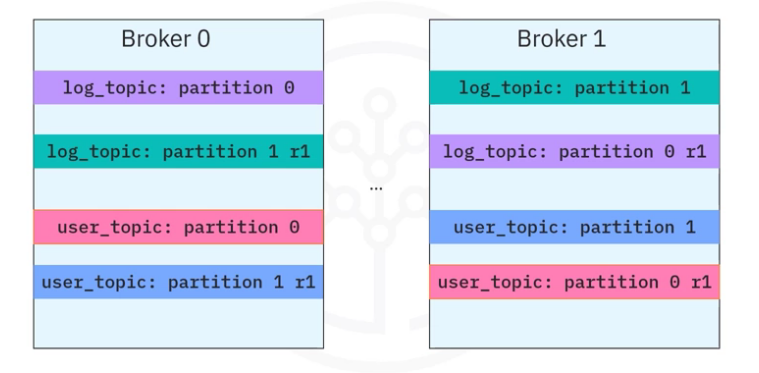
Let’s look at an example of how the data is organized as topics in the brokers.
- A log_topic and a transaction topic in broker 0,
- a payment_topic and a gps_topic in broker 1
- a user_click_topic and user_search_topic in broker 2.
Each broker contains one or many topics. You can think of a topic as a database to store specific types of events such as logs, transactions, and metrics.
- Brokers manage to save published events into topics and distribute the events to subscribed consumers.
- Like many other distribution systems, Kafka implements the concepts of partitioning and replicating.
- It uses topic partitions and replications to increase fault tolerance and throughput so that event publication and consumption can be done in parallel with multiple brokers.
- In addition, even if some brokers are down, kafka clients are still able to work with the target topics replicated in other working brokers.
For example
- a log_topic has been separated into two partitions (0,1)
- a user topic has been separated into two partitions (0,1)
- each topic partitioned is duplicated into two replications and
- stored in different brokers.
CLI Command
The Kafka CLI, or command-line interface client, provides a collection of powerful script files for users to build an event streaming pipeline. The Kafka topics script is the one you will be using often to manage topics in a Kafka cluster.
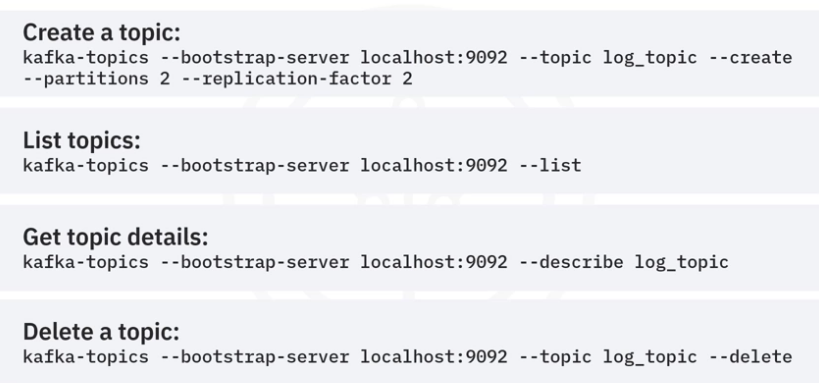
- The first one is to create a topic. We are trying to create a topic called log_topic with two partitions and two replications. One important note here is that many Kafka commands like kafka-topics require users to refer to a running Kafka cluster with a host and a port, such as a local host with port 9092.
- After you have created some topics, you can check all created topics in the cluster using the list option.
- And if you want to check more details of a topic such as partitions and replications. You can use the describe option and
- you can delete a topic using the delete option.
Producer
Producers are client applications that publish events to topic partitions according to the same order as they are published.
- When publishing an event in a Kafka producer, an event can be optionally associated with a key.
- Events associated with the same key will be published to the same topic partition.
- Events not associated with any key will be published to topic partitions in rotation.
Example
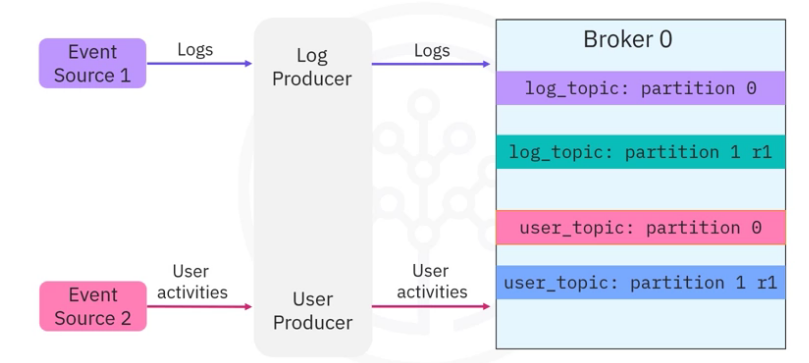
- Suppose you have an Event Source 1 which generates various log entries and
- an Event Source 2 which generates user activity tracking records.
- Then you can create a Kafka producer to publish log records to log topic partitions and
- a user producer to publish user activity events to user topic partitions, respectively.

When you publish events in producers, you can choose to associate events with a key, for example, an application name or a user ID. Similar to the Kafka topic CLI, Kafka provides the Kafka producer CLI for users to manage producers.
- The most important aspect is starting a producer to write or publish events to a topic.
- Here you start a producer and point it to the log_topic.
- Then you can type some messages in the console to start publishing events.
- For example, log1, log2, and log3.
- You can provide keys to events to make sure the events with the same key will go to the same partition.
- Here you are starting a producer to user_topic with the parse.key
- option to be true and you also specify the key.separator to be comma
- Then you can write messages as follows, key, user1, value login website, key, user1, value, click the top item and key, user1, value, logout website.
- Accordingly, all events about user one will be saved in the same partition to facilitate the reading for consumers.
Consumer
Once events are published and properly stored in topic partitions, you can create consumers to read them.
Consumers are client applications that can subscribe to topics and read the stored events. Then event destinations can further read events from Kafka consumers.
- Consumers read data from topic partitions in the same order as they are published.
- Consumers also store an offset for each topic partition as the last read position.
- With the offset, consumers are guaranteed to read events as they occur.
- A playback is also possible by resetting the offset to zero.
- This way, the consumer can read all events in the topic partition from the beginning.
In Kafka, producers and consumers are fully decoupled. As such, producers don’t need to synchronize with consumers, and after events are stored in topics, consumers can have independent schedules to consume them.
- To read published log and user events from topic partitions, you will need to create
- log and user consumers and make them subscribe to corresponding topics.
- Then Kafka will push the events to those subscribed consumers.
- Then the consumers will further send to event destinations.
Start Consumer
To start a consumer using the Kafka consumer script.

- Let’s read events from the log_topic.
- You just need to run the Kafka console consumer script and
- specify a Kafka cluster and the topic to subscribe to.
- You can subscribe to and read events from the topic log_topic.
- Then the started consumer will read only the new events starting from the last partition offset.
- After those events are consumed, the partition offset for the consumer will also be updated and committed back to Kafka.
- Very often a user wants to read all events from the beginning as a playback of all historical events. To do so, you just need to add the from-beginning option.
- Now you can read all events starting from offset 0.
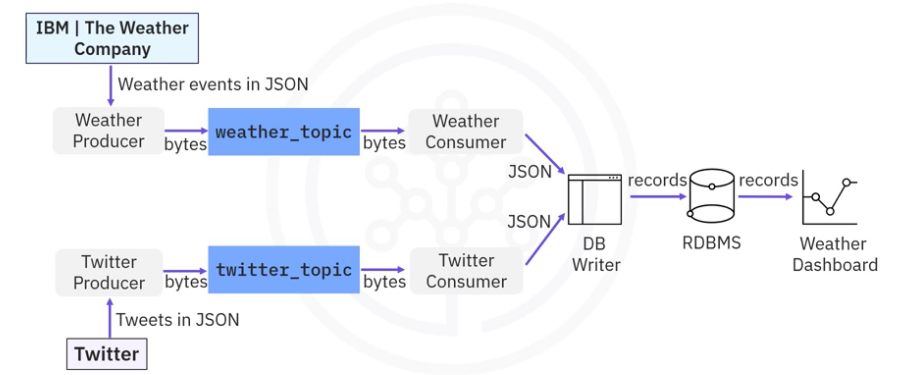
Let’s have a look at a more concrete example to help you understand how to build an event streaming pipeline end to end.
- Suppose you want to collect and analyze weather and Twitter event streams so that you can correlate how people talk about extreme weather on Twitter.
- Here you can use two event sources: IBM weather API to obtain real time and forecasted weather data in JSON format.
- Twitter API to obtain real-time tweets and mentions also in JSON format.
- To receive weather and Twitter JSON data in Kafka, you then create a weather topic
- and a Twitter topic in a Kafka cluster with some partitions and replications.
- To publish weather and Twitter JSON data to the two topics, you need to create a weather producer and a Twitter producer.
- The event’s JSON data will be serialized into bytes and saved in Kafka topics.
- To read events from the two topics, you need to create a weather consumer and a Twitter consumer.
- The bytes stored in Kafka topics will be deserialized into event JSON data.
- If you now want to transport the weather and Twitter event JSON data from the consumers to a relational database, you will use a DB writer to parse those JSON files and create database records,
- and then you can write those records into a database using SQL insert statements.
- Finally, you can query the database records from the relational database and visualize and analyze them in a dashboard to complete the end-to-end pipeline.
Architecture
Kafka Clients
Kafka has a distributed client-server architecture. For the server side, Kafka is a cluster with many associated servers called broker, acting as the event broker to receive, store, and distribute events. It also has some servers that run “Kafka Connect” to import and export data as event streams.
However, Kafka Raft, or KRaft, is now used to eliminate Kafka’s reliance on ZooKeeper for metadata management.
- It is a consensus protocol that streamlines Kafka’s architecture by consolidating metadata responsibilities within Kafka itself using Kafka Controllers.
Producerssend or publish data to theTopicConsumerssubscribe to the topic to receive data.- Kafka uses a TCP-based network communication protocol to exchange data between clients and servers.
For the client side, Kafka provides different types of clients, such as:
- Kafka CLI, which is a collection of shell scripts to communicate with a Kafka server
- Many high-level programming APIs such as Python, Java, and Scala
- REST APIs
- Specific third-party clients made by the Kafka community
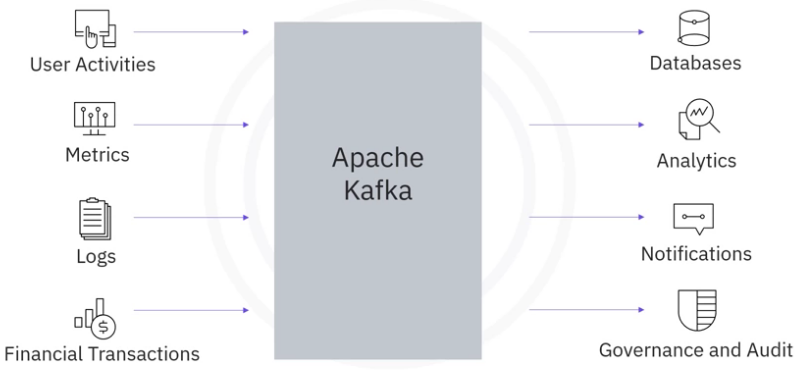
Apache Kafka is an open source project which has become the most popular ESP.
- Kafka is a comprehensive platform and can be used in many application scenarios.
- Kafka was originally used to track user activities such as keyboard strokes, mouse clicks, page views, searches, gestures, screen time, and so on.
- Now, Kafka is also suitable for all kinds of metric streaming such as sensor readings, GPS, and hardware and software monitoring.
- For enterprise applications and infrastructure with a huge number of logs, Kafka can be used to collect and integrate them into a centralized repository.
- For banks, insurance, or fintech companies, Kafka is widely used for payments and transactions.
- Essentially, you can use Kafka when you want high throughput and reliable data transportation services among various event sources and destinations.
- All events will be ingested in Kafka and become available for subscriptions and consumption, including further data storage and movement to other online or offline databases and backups.
- Real time processing and analytics including dashboard, machine learning, AI algorithms, and so on, generating notifications such as email, text
- messages, and instant messages, or data governance and auditing to make sure sensitive data such as bank transactions are complying with regulations.
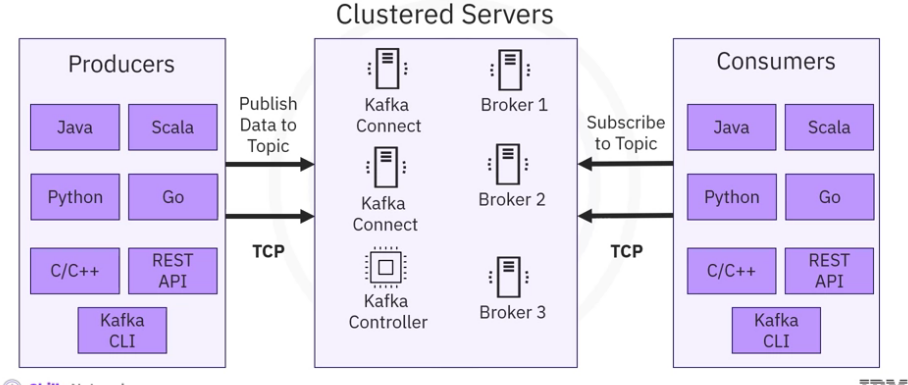
- Kafka is a distributed, real time event streaming platform that adheres to client server architecture.
- Kafka runs as a cluster of broker servers, acting as the event broker to receive events from the producers, store the streams of records, and distribute events.
- It also has servers that run Kafka Connect to import and export data as event streams.
- Using Kafka controllers, producers send or publish data to the topic, and the consumers subscribe to the topic to receive data.
- Kafka uses a transmission control protocol, TCP based network communication protocol, to exchange data between clients and servers.
- For the client side, Kafka provides different types of clients such as Kafka command line interface, CLI.
- A collection of shell scripts to communicate with the Kafka server, several high level programming APIs such as Java, Scala, Python, Go, C, and
- C++, rest APIs, and some specific third party clients made by the Kafka community.
Kafka Python
Let’s focus on the Kafka Python client called kafka-python.
kafka-pythonis a Python client for the Apache Kafka distributed stream processing system, which aims to provide similar functionalities as the main Kafka Java client.- With
kafka-python, you can easily interact with your Kafka server such as managing topics, publish, and consume messages in Python programming language. - You must install
kafka-pythonusingpip3 installerto use it with a Python client.
KafkaAdminClient
The main purpose of KafkaAdminClient class is to enable fundamental administrative management operations on kafka server such as creating/deleting topic, retrieving, and updating topic configurations and so on.
- To use
KafkaAdminClient, you first need to define and create aKafkaAdminClientobject.
admin_client = KafkaAdminClient(bootstrap_servers="localhost:9092", client_id='test')
# OUTOUT
bootstrap_servers="localhost:9092" argument specifies the host/IP and port that the consumer should contact
to bootstrap initial cluster metadata
client_id specifies an id of current admin clientCreate Topic
- The most common use of the
admin_clientis managing topics, such as creating and deleting topics. To create topics, you must first define an empty topic list - Then, you use the
NewTopicclass to create a topic with name, partition, and replication factors. For example, name equalsbankbranch, partition nums equals 2, and replication factor equals 1. - You can use
create_topics(...)method to create topics.
topic_list = []
new_topic = NewTopic(name="bankbranch", num_partitions= 2, replication_factor=1)
topic_list.append(new_topic)
admin_client.create_topics(new_topics=topic_list)Descrive Topic
- After the topics are created, you can check its configuration details using the
describe_configs()method. - Note: The
describetopic operation used above is equivalent to usingkafka-topics.sh --describein Kafka CLI client.
configs = admin_client.describe_configs(
config_resources=[ConfigResource(ConfigResourceType.TOPIC, "bankbranch")])KafkaProducer
Having created the new bankbranch topic, you can start producing messages.
For kafka-python, you will use KafkaProducer class to produce messages. Since many real-world message values are in the JSON format, let’s look at how to publish JSON messages as an example
- First, let’s define and create a
KafkaProducer. - Since Kafka produces and consumes messages in raw bytes, you need to encode our JSON messages and serialize them into bytes. For the
value_serializerargument, you will define a lambda function to take a Python dict/list object and serialize it into bytes. - Then, with the
KafkaProducercreated, you can use it to produce two ATM transaction messages in JSON format - The first argument specifies the topic
bankbranchto be sent and the second argument represents the message value in a Python dict format and will be serialized into bytes. - Note: The above producing message operation is equivalent to using
kafka-console-producer.sh --topicin Kafka CLI client.
producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'))
producer.send("bankbranch", {'atmid':1, 'transid':100})
producer.send("bankbranch", {'atmid':2, 'transid':101})KafkaConsumer
In the previous step, you published two JSON messages. Now, you can use the KafkaConsumer class to consume the messages.
- Define and create a
KafkaConsumersubscribing to the topicbankbranch - Once the consumer is created, it will receive all available messages from the topic
bankbranch. Then, you can iterate and print them with the following code snippet:
consumer = KafkaConsumer('bankbranch')
for msg in consumer:
print(msg.value.decode("utf-8"))Summary
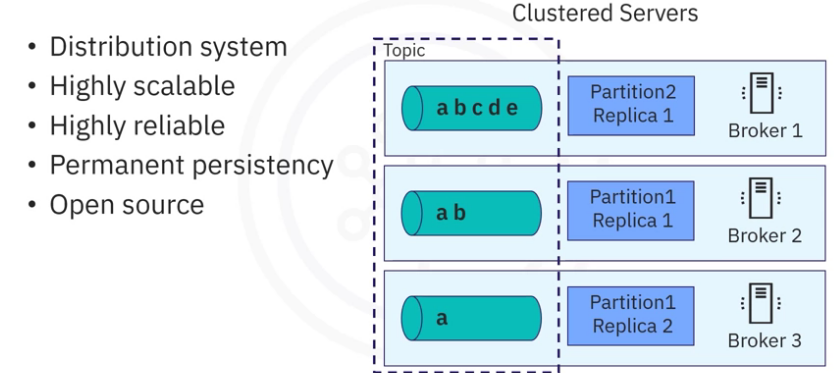
- Kafka is a distribution system, which makes it highly scalable to handle high data throughput and concurrency.
- A Kafka cluster normally has multiple event brokers which can handle event streaming in parallel.
- Kafka is very fast and highly scalable.
- Kafka also divides event storage into multiple partitions and replications, which makes it fault-tolerant and highly reliable.
- Kafka stores the events permanently. As such, event consumption can be done whenever suitable for consumers without a deadline, and
- Kafka is open source
Managed ESP
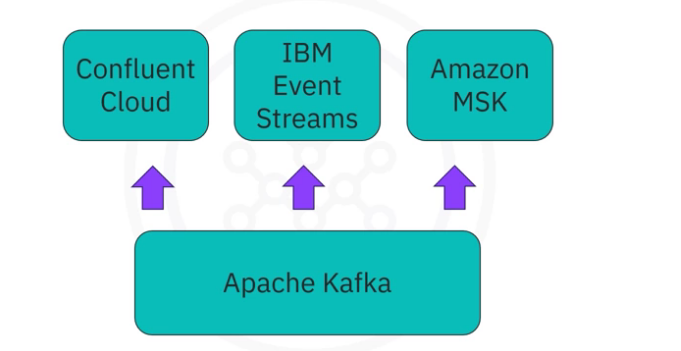
Deploying a Kafka cluster requires extensive efforts for tuning infrastructure and consistently adjusting the configurations, especially for enterprise-level deployments.
- Several commercial service providers offer an on-demand ESP as a service to meet streaming requirements.
- Many of them are built on top of Kafka and provide added value for customers.
- Some well known ESP providers include Confluent Cloud, which provides customers with fully managed Kafka services either on premises or on cloud.
- IBM event streams, which is also based on Kafka and provides many add-on services such as enterprise-grade security, disaster recovery, and 24/7 cluster monitoring.
- Amazon managed streaming for Apache Kafka, which is also a fully managed service to facilitate the build and deployment of Kafka.
API
Kafka has four core APIs:
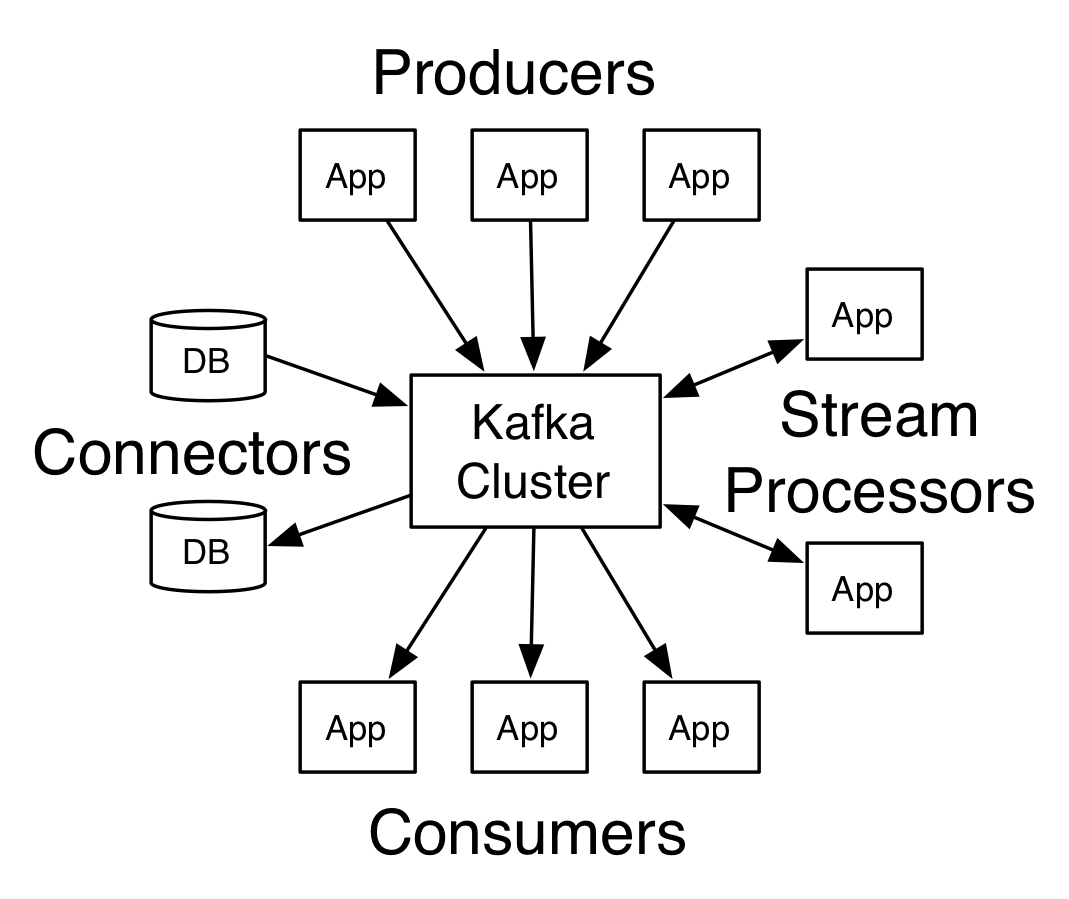
- The Producer API allows an application to publish a stream records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
Weather Stream
For stream processing applications based on Kafka, a straightforward way is to
- implement an ad hoc data processor to read events from one topic,
- process them, and
- publish them to another topic.
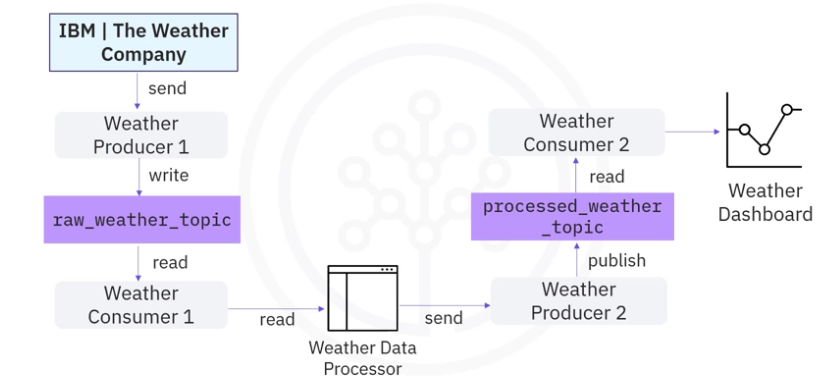
- You first request raw weather JSON data from a weather API,
- and you start a weather producer to publish
- the raw data into a raw_weather_topic.
- Then you start a consumer to read the raw weather data from the weather topic.
- Next, you create an ad hoc data processor to filter the raw weather data to only include extreme weather events, such as very high temperatures.
- Such a processor could be a simple script file or an application which works with Kafka clients to read and write data from Kafka.
- Afterwards, the processor sends the processed data to another producer and it gets
- published to a processed_weather_topic.
- Finally, the processed weather data will be consumed by a dedicated consumer and
- sent to a dashboard for visualization.
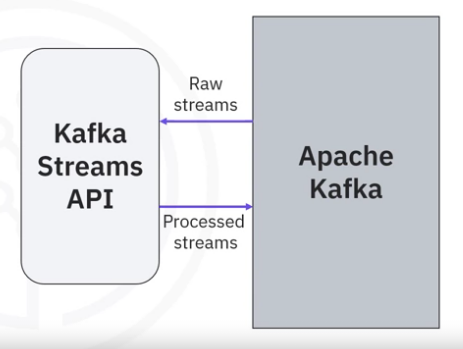
Such ad hoc processors may become complicated if you have many different topics to be processed. A solution that may solve these challenges is Kafka. It provides the Streams API to facilitate stream processing.
- Kafka Streams API is a simple client library aiming to facilitate data processing in event streaming pipelines.
- It processes and analyzes data stored in Kafka topics.
- Thus, both the input and output of the Streams API are Kafka topics.
- Additionally, Kafka Streams API ensures that each record will only be processed once.
- Finally, it processes only one record at a time.
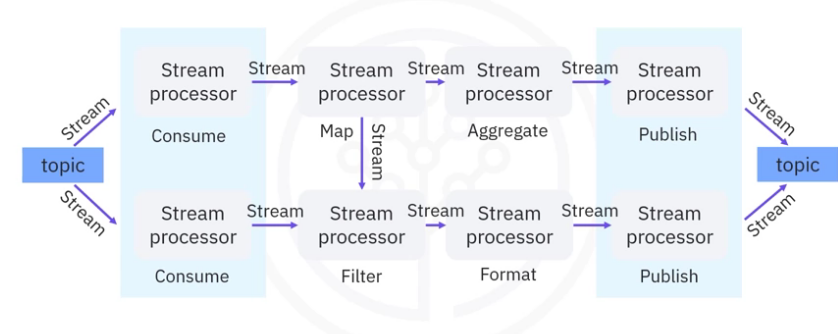
Kafka Streams API is based on a computational graph called a stream processing topology, shown above:
- In this topology, each node is a stream processor,
- which receives streams from its upstream processor;
- performs data transformations,
- such as mapping, filtering, formatting, and aggregation; and produces
- output streams to its downstream stream processors.
- Thus, the edges of the graph are the I/O streams.
There are two special types of processors.
- On the left, you can see the source processor which has no upstream processors. A source processor acts like a consumer, which consumes streams from Kafka topics and forwards the process streams to its downstream processors.
- On the right, you can see the sink processor, which has no downstream processors. A sink processor acts like a producer which publishes the received stream to a Kafka topic.
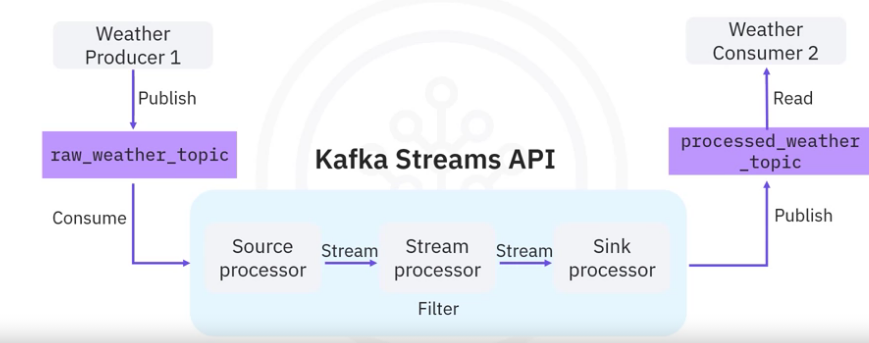
Let’s redesign the previous weather stream processing application with Kafka Streams API. Suppose you have a raw_weather_topic and a processed_weather_topic in Kafka.
- Now, instead of spending a huge amount of effort developing an ad hoc processor, you could just plug in the Kafka Streams API here.
- In the Kafka Streams topology, we have three stream processors,
- the source processor that consumes raw weather streams from the raw_weather_topic and
- forwards the weather stream to the stream processor to
- filter the stream based on high temperature.
- Then the filtered stream will be forwarded to the sink processor,
- which then publishes the output to the processed_weather_topic.